Sistemas de Computadoras CDC6000
VER VIDEO
Teléfonos Inteligentes e Intenet
CDC fue una compañía americana fabricante de computadoras, inicio sus operaciones en 1957 con la computadora 1604 de transistores, después siguieron la 160, el sistema 3000 y otras muchas más. En México se creo en 1965 la compañía CDM representante o filial de CDC. El sistema que le dio el éxito y de colocarse en 1965 como el principal fabricante de super computadoras fue el sistema 6000 con una arquitectura y organización avanzada y original. Todas las computadoras del sistema 6000 fueron construidas con transistores de alta velocidad y con tecnología planar y fué base del desarrollo de los circuitos integrados y microprocesadores.


Específicamente la 6600 fue la primera computadora que se construyo y la describiremos a continuación.
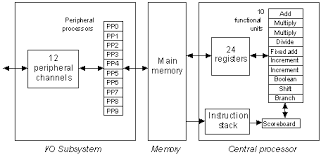
Una computadora tiene Entradas, Memoria, un Procesador Central y Salidas. Un sistema es un conjunto de elementos o unidades relacionados entre si con un objetivo común. Una computadora como sistema contiene unidades de Entrada de datos e instrucciones y se almacenan en la unidad de Memoria se obtienen las instrucciones y datos, son procesados por la unidad de procesamiento central CPU y los resultados se llevan a las unidades de Salida como datos o información.
La computadora 6600 físicamente esta en un gabinete en forma de cruz con cuatro bahías. Una bahía contiene los PPs, el CPU y el panel dead start, Otra puede tener otro CPU o memoria MEM, las otras 2 contiene más memoria MEM. El panel de DeadStart contiene una matrix de 12x12 switchs y sirve para introducir un pequeño programa para cargar el sistema operativo o diagnósticos de mantenimiento de cinta o disco magnético e inicie su operación. Cada bahía tiene un sistema refrigerante de un compresor y un condensador que hace circular por cada chasis una tubería de freón que recoge el calor generado por los circuitos de los módulos y es llevado al condensador para enfriarse y así continuar circulando. Una bahía tiene 4 chasis y cada chasis tiene módulos de circuitos y de memoria en racks horizontales. Cada módulo de 8cmx7cmx2cm tiene resistencias R, capacitores C, diodos D y transistores T. Los módulos de memoria son más grandes. En total hay aproximadamente unos 400 mil transistores.
El espacio del gabinete es de 4mx4mx2m, más el espacio de controladores y equipo periférico, se necesita por lo menos 25mx25mx3m de espacio para todo el sistema de computación, incluyendo la fuente de energía de CA del motogenerador y la fuente de baterías de emergencia, el equipo de aire acondicionado para controlar la temperatura ambiente. Es un pequeño vecindario de muebles y gabinetes metálicos con espacios para caminar entre ellos, restringido a pocas personas como operadores e ingenieros de mantenimiento


.
VER VIDEO
Teléfonos Inteligentes e Intenet
CDC fue una compañía americana fabricante de computadoras, inicio sus operaciones en 1957 con la computadora 1604 de transistores, después siguieron la 160, el sistema 3000 y otras muchas más. En México se creo en 1965 la compañía CDM representante o filial de CDC. El sistema que le dio el éxito y de colocarse en 1965 como el principal fabricante de super computadoras fue el sistema 6000 con una arquitectura y organización avanzada y original. Todas las computadoras del sistema 6000 fueron construidas con transistores de alta velocidad y con tecnología planar y fué base del desarrollo de los circuitos integrados y microprocesadores.


Específicamente la 6600 fue la primera computadora que se construyo y la describiremos a continuación.
Una computadora tiene Entradas, Memoria, un Procesador Central y Salidas. Un sistema es un conjunto de elementos o unidades relacionados entre si con un objetivo común. Una computadora como sistema contiene unidades de Entrada de datos e instrucciones y se almacenan en la unidad de Memoria se obtienen las instrucciones y datos, son procesados por la unidad de procesamiento central CPU y los resultados se llevan a las unidades de Salida como datos o información.
La computadora 6600 físicamente esta en un gabinete en forma de cruz con cuatro bahías. Una bahía contiene los PPs, el CPU y el panel dead start, Otra puede tener otro CPU o memoria MEM, las otras 2 contiene más memoria MEM. El panel de DeadStart contiene una matrix de 12x12 switchs y sirve para introducir un pequeño programa para cargar el sistema operativo o diagnósticos de mantenimiento de cinta o disco magnético e inicie su operación. Cada bahía tiene un sistema refrigerante de un compresor y un condensador que hace circular por cada chasis una tubería de freón que recoge el calor generado por los circuitos de los módulos y es llevado al condensador para enfriarse y así continuar circulando. Una bahía tiene 4 chasis y cada chasis tiene módulos de circuitos y de memoria en racks horizontales. Cada módulo de 8cmx7cmx2cm tiene resistencias R, capacitores C, diodos D y transistores T. Los módulos de memoria son más grandes. En total hay aproximadamente unos 400 mil transistores.
El espacio del gabinete es de 4mx4mx2m, más el espacio de controladores y equipo periférico, se necesita por lo menos 25mx25mx3m de espacio para todo el sistema de computación, incluyendo la fuente de energía de CA del motogenerador y la fuente de baterías de emergencia, el equipo de aire acondicionado para controlar la temperatura ambiente. Es un pequeño vecindario de muebles y gabinetes metálicos con espacios para caminar entre ellos, restringido a pocas personas como operadores e ingenieros de mantenimiento

.
Ahora
en la palma de la mano con un teléfono inteligente tenemos una pequeña
supercomputadora de varios microprocesadores SOC en un mundo de formas
geométricas con dimensiones muy pequeñas hechas con millones de
transistores donde solo circulan millones de electrones.
La gran diferencia de la supercomputadora y la pequeña supercomputadora es el peso de toneladas-gramos, dimensiones de metros-centimétros, velocidad de megahz-gigahz, funciones pocas-muchas y el costo de millones-miles.

La gran diferencia de la supercomputadora y la pequeña supercomputadora es el peso de toneladas-gramos, dimensiones de metros-centimétros, velocidad de megahz-gigahz, funciones pocas-muchas y el costo de millones-miles.

Unidad de Procesamiento Central CPU
Describiremos la arquitectura del sistema 6000 con el modelo 6600, contiene un CPU con 8 registros A0-7 de 18 bis de direccionamiento a memoria central A1-5 para lectura de memoria A6-7 para escritura en memoria. También 8 registros index B0-7 de 18 bits y 8 registros de datos X0-7 de 60 bits, X1-5 para leer datos de memoria y X6-7 para escribir datos a memoria. Cuando se ejecutan la instrucción Set en A1-5 se leen los datos de memoria en X1-5. Con Set A6-7 los datos de X6-7 se escriben en memoria. Además tiene 10 unidades funcionales de 2 Multiply, Divide, Boolean, Fixed Add, Floating Add, Shif, 2 Increment y Branch.
El formato de las instrucciones son de 15 y 30 bits.
El formato de 15b es.
F(3)M(3)i(3)j(3)k(3)
El formato de 30b es.
F(3)M(3)i(3)j(3)K(18)
Las instrucciones contienen un código FM y 3 direcciones, 2 son los operandos j y k y la otra i el resultado, K indica una dirección en la memoria central.
Utilizan el Sistema Numérico Octal
0-0, 1-1, 2-2, 3-3, 4-4, 5-5, 6-6, 7-7
10-8, 11-9, 12-10, 13-11, 14-12...
Los números octales facilitan representar las instrucciones y datos binarios de 0 y 1 del lenguaje de máquina que solo entiende la CDC6000 para procesar las instrucciones de un programa de CPU.
Describiremos la arquitectura del sistema 6000 con el modelo 6600, contiene un CPU con 8 registros A0-7 de 18 bis de direccionamiento a memoria central A1-5 para lectura de memoria A6-7 para escritura en memoria. También 8 registros index B0-7 de 18 bits y 8 registros de datos X0-7 de 60 bits, X1-5 para leer datos de memoria y X6-7 para escribir datos a memoria. Cuando se ejecutan la instrucción Set en A1-5 se leen los datos de memoria en X1-5. Con Set A6-7 los datos de X6-7 se escriben en memoria. Además tiene 10 unidades funcionales de 2 Multiply, Divide, Boolean, Fixed Add, Floating Add, Shif, 2 Increment y Branch.
El formato de las instrucciones son de 15 y 30 bits.
El formato de 15b es.
F(3)M(3)i(3)j(3)k(3)
El formato de 30b es.
F(3)M(3)i(3)j(3)K(18)
Las instrucciones contienen un código FM y 3 direcciones, 2 son los operandos j y k y la otra i el resultado, K indica una dirección en la memoria central.
Utilizan el Sistema Numérico Octal
0-0, 1-1, 2-2, 3-3, 4-4, 5-5, 6-6, 7-7
10-8, 11-9, 12-10, 13-11, 14-12...
Los números octales facilitan representar las instrucciones y datos binarios de 0 y 1 del lenguaje de máquina que solo entiende la CDC6000 para procesar las instrucciones de un programa de CPU.
INSTRUCCIONES DEL CPU
Operación Instrucción Descripción
BRANCH UNIT
0000K PS K Program stop
0100K RJ K Return jump to K
011jK RE Bj+/-K Read Extended Core Storage (ECS)
012jK WE Bj+/-K Write Extended Core Storage (ECS)
013jK XJ Bj+/-K Central Exchange jump to (Bj)+/-K
02i0K JP Bi+K Jump to K + (Bi)
030jK ZR Xj,K Jump to K when (Xj) = 0
031jK NZ Xj,K Jump to K when (Xj) <> 0
032jK PL Xj,K Jump to K when (Xj) sign is plus
033jK MI or NG Xj,K Jump to K when (Xj) sign is minus
034jK IR Xj,K Jump to K when (Xj) in range
035jK OR Xj,K Jump to K when (Xj) not in range
036jK DF Xj,K Jump to K when (Xj) definite0
037jK ID Xj,K Jump to K when (Xj) indefinite
0400K EQ K jump to K (uncond)
04ijK EQ Bi,Bj,K Branch to K when (Bi) = (Bj)
04i0K ZR Bi,K Branch to K when (Bi) = 0
05ijK NE Bi,Bj,K Branch to K when (Bi) unequal (Bj)
05i0K NZ Bj,K Branch to K when (Bi) non-zero
06ijK GE Bi,Bj,K Branch to K when (Bi) >= (Bj)
06i0K EQ Bi,Bj,K Branch to K when (Bi) >= 0
06ijK LE Bj,Bi,K Branch to K when (Bj) <= (Bi)
060jK LE Bj,K Branch to K when (Bj) <= 0
07ijK LT Bi,Bj,K Branch to K when (Bi) < (Bj)
07i0K LT or NG Bi,K Branch to K when (Bi) < 0
07ijK GT Bj,Bi,K Branch to K when (Bi) > (Bj)
070jK GT or MI Bj,K Branch to K when (Bi) > 0
BOOLEAN UNIT
10ijj BXi Xj Copy (Xj) to Xi
11ijk BXi Xj*Xk Logical product (AND) of (Xj) and (Xk) to Xi
12ijk BXi Xj+Xk Logical sum of (Xj) and (Xk) to Xi
13ijk BXi Xj-Xk Logical difference of (Xj) and (Xk) to Xi
14ijj BXi -Xj Copy complement of (Xj) to Xi
15ijk BXi -Xk*Xj Logical product of (Xj) and complement (Xk) to Xi
16ijk BXi -Xk+Xj Logical sum of (Xj) and complement (Xk) to Xi
17ijk BXi -Xk-Xj Logical difference of (Xj) and complement (Xk) to Xi
SHIFT UNIT
20ijk LXi jk Logical shift (Xi) by jk (left shift)
21ijk AXi jk Arithmetic shift (Xi) by jk (right shift)
22ijk LXi Bj, Xk Logical shift (Xk) by (Bj) to Xi
22iji LXi Bj Logical shift (Xi) by (Bj) to Xi
22i0k LXi Xk Transmit (Xk) to Xi
23ijk AXi Bj, Xk Arithmetic shift (Xk) by (Bj) to Xi
23iji AXi Bj Arithmetic shift (Xi) by (Bj) to Xi
23i0k AXi Xk Transmit (Xk) to Xi
24ijk NXi Bj Xk Normalize (Xk) to Xi and Bj
24i0i NXi Normalize (Xi) to Xi
24iji NXi, Bj Normalize (Xi) to Xi and Bj
24i0k NXi Xk Normalize (Xk) to Xi
25ijk ZXi Bj Xk Round and normalize (Xk) to Xi and Bj
25i0i ZXi Round and normalize (Xi) to Xi
25iji ZXi, Bj Round and normalize (Xi) to Xi and Bj
25i0k ZXi Xk Round and normalize (Xk) to Xi
26ijk UXi, Bj Xk Unpack (Xk) to Xi and Bj
26i0i UXi Unpack (Xi) to Xi
26iji UXi, Bj Unpack (Xi) to Xi and Bj
26i0k UXi Xk Unpack (Xk) to Xi
27ijk PXi Xk,Bj Pack (Xk) and (Bj) to Xi
27i0i PXi Pack (Xi) to Xi
27iji PXi Bj Pack (Xi) and (Bj) to Xi
27i0k PXi Xk Pack (Xk) to Xi
ADD UNIT
30ijk FXi Xj+Xk Sum of (Xj) plus (Xk) to Xi
31ijk FXi Xj-Xk Difference of (Xj) minus (Xk) to Xi
32ijk DXi Xj+Xk Double-precision sum of (Xj) plus (Xk) to Xi
33ijk DXi Xj-Xk Double-precision difference of (Xj) minus (Xk) to Xi
34ijk RXi Xj+Xk Rounded sum of (Xj) plus (Xk) to Xi
35ijk RXi Xj-Xk Rounded difference of (Xj) minus (Xk) to Xi
LONG ADD UNIT
36ijk IXi Xj+Xk Integer sum of (Xj) plus (Xk) to Xi
37ijk IXi Xj-Xk Integer difference of (Xj) minus (Xk) to Xi
MULTIPLAY UNIT
40ijk FXi Xj*Xk Product of (Xj) times (Xk) to Xi
41ijk RXi Xj*Xk Rounded product of (Xj) times (Xk) to Xi
42ijk IXi Xj*Xk Integer product of (Xj) times (Xk) to Xi
42ijk DXi Xj*Xk Double-precision product of (Xj) times (Xk) to Xi
43ijk MXi jk Mask of +/-jk bits to Xi
44ijk FXi Xj/Xk Divide(Xj) by (Xk) to Xi
45ijk RXi Xj/Xk Rounded divide (Xj) by (Xk) to Xi
46000 NO No-operation
47ikk CXi Xk Population count of (Xk) to Xi (note)
INCREMENT UNIT
50ijK SAi Aj+K (Aj) plus K to Ai
51ijK SAi Bj+K (Bj) plus K to Ai
51i0K SAi K K to Ai
52ijK SAi Xj+K (Xj) plus K to Ai
53ijk SAi Xj+Bk (Xj) plus (Bk) to Ai
53ij0 SAi Xj (Xj) to Ai
54ijk SAi Aj+Bk (Aj) plus (Bk) to Ai
54ij0 SAi Aj (Aj) to Ai
55ijk SAi Aj-Bk (Aj) minus (Bk) to Ai
56ijk SAi Bj+Bk (Bj) plus (Bk) to Ai
56ij0 SAi Bj (Bj) to Ai
57ijk SAi Bj-Bk (Bj) minus (Bk) to Ai
57i0k SAi -Bk Minus (Bk) to Ai
60ijK SBi Aj+K (Aj) plus K to Bi
61ijK SBi Bj+K (Bj) plus K to Bi
61i0K SBi K K to Bi
62ijK SBi Xj+K (Xj) plus K to Bi
63ijk SBi Xj+Bk (Xj) plus (Bk) to Bi
63ij0 SBi Xj (Xj) to Bi
64ijk SBi Aj+Bk (Aj) plus (Bk) to Bi
64ij0 SBi Aj (Aj) to Bi
65ijk SBi Aj-Bk (Aj) minus (Bk) to Bi
66ijk SBi Bj+Bk (Bj) plus (Bk) to Bi
66ij0 SBi Bj (Bj) to Bi
67ijk SBi Bj-Bk (Bj) minus (Bk) to Bi
67i0k SBi -Bk (Bj) to Bi
70ijK SXi Aj+K (Aj) plus K to Xi
71ijK SXi Bj+K (Bj) plus K to Xi
71i0K SXi K K to Xi
72ijK SXi Xj+K (Xj) plus K to Xi
73ijk SXi Xj+Bk (Xj) plus (Bk) to Xi
73ij0 SXi Xj (Xj) to Xi (18 bit transf!)
74ijk SXi Aj+Bk (Aj) plus (Bk) to Xi
74ij0 SXi Aj (Aj) to Xi
75ijk SXi Aj-Bk (Aj) minus (Bk) to Xi
76ijk SXi Bj+Bk (Bj) plus (Bk) to Xi
76ij0 SXi Bj (Bj) to Xi
77ijk SXi Bj-Bk (Bj) minus (Bk) to Xi
77i0k SXi -Bk (Bj) to Xi
CMU
4640K IM K Move indirect data to word at K
464jK IM Bj+K Move data to word at (Bj)+K
464j0 IM Bj Move data to word at (Bj)
4650K DM K Move direct data to word at K
466 CC & Compare collated
467 CU & Compare un collated
Logical operations
* Logical Product is the boolean AND operation
* Logical addition is the boolean OR operation
* Logical difference is the boolean Exclusive OR (EXOR) operation
En una palabra de 60b caben 4 instrucciones de 15b o 2 instrucciones de 30b. Un programa es una secuencia de palabras con instrucciones. Al ejecutar el programa se obtiene la primera palabra y puede contener 4 instrucciones de 15b o 2 de 30b o combinaciones de 2 de 15b y 1 de 30b. Para los datos usa enteros de Punto Fijo de 60b el bit más a la izquierda representa el signo, 0 positivo y 1 negativo y datos de Punto Flotante en 60 bits en 0-47 la base o coeficiente el bit más a la izquierda es el signo y en 48-59 el exponente el bit más a la izquierda el signo. Para representar caracteres alfanuméricos usa el código display de 6 bits y en una palabra de 60 bits caben 10 caracteres. Dependiendo del código realiza las operaciónes en alguna de las 10 unidades funcionales en paralelo, cuando termina de procesar las instrucciones de la palabra, lee la siguiente palabra con instrucciones, se ejecutan y así continúa hasta la última instrucción del programa.
Para la 6400 tiene los mismos registros, la única diferencia, solo tiene una unidad funcional o mejor dicho una unidad aritmética secuencial o unificada Unified que ejecuta todas las instrucciones anteriores secuencialmente.
El modelo 6500 tiene 2 CPUs 6400 y el modelo 6700 también tiene 2 CPUs una 6600 y una 6400.

Operación Instrucción Descripción
BRANCH UNIT
0000K PS K Program stop
0100K RJ K Return jump to K
011jK RE Bj+/-K Read Extended Core Storage (ECS)
012jK WE Bj+/-K Write Extended Core Storage (ECS)
013jK XJ Bj+/-K Central Exchange jump to (Bj)+/-K
02i0K JP Bi+K Jump to K + (Bi)
030jK ZR Xj,K Jump to K when (Xj) = 0
031jK NZ Xj,K Jump to K when (Xj) <> 0
032jK PL Xj,K Jump to K when (Xj) sign is plus
033jK MI or NG Xj,K Jump to K when (Xj) sign is minus
034jK IR Xj,K Jump to K when (Xj) in range
035jK OR Xj,K Jump to K when (Xj) not in range
036jK DF Xj,K Jump to K when (Xj) definite0
037jK ID Xj,K Jump to K when (Xj) indefinite
0400K EQ K jump to K (uncond)
04ijK EQ Bi,Bj,K Branch to K when (Bi) = (Bj)
04i0K ZR Bi,K Branch to K when (Bi) = 0
05ijK NE Bi,Bj,K Branch to K when (Bi) unequal (Bj)
05i0K NZ Bj,K Branch to K when (Bi) non-zero
06ijK GE Bi,Bj,K Branch to K when (Bi) >= (Bj)
06i0K EQ Bi,Bj,K Branch to K when (Bi) >= 0
06ijK LE Bj,Bi,K Branch to K when (Bj) <= (Bi)
060jK LE Bj,K Branch to K when (Bj) <= 0
07ijK LT Bi,Bj,K Branch to K when (Bi) < (Bj)
07i0K LT or NG Bi,K Branch to K when (Bi) < 0
07ijK GT Bj,Bi,K Branch to K when (Bi) > (Bj)
070jK GT or MI Bj,K Branch to K when (Bi) > 0
BOOLEAN UNIT
10ijj BXi Xj Copy (Xj) to Xi
11ijk BXi Xj*Xk Logical product (AND) of (Xj) and (Xk) to Xi
12ijk BXi Xj+Xk Logical sum of (Xj) and (Xk) to Xi
13ijk BXi Xj-Xk Logical difference of (Xj) and (Xk) to Xi
14ijj BXi -Xj Copy complement of (Xj) to Xi
15ijk BXi -Xk*Xj Logical product of (Xj) and complement (Xk) to Xi
16ijk BXi -Xk+Xj Logical sum of (Xj) and complement (Xk) to Xi
17ijk BXi -Xk-Xj Logical difference of (Xj) and complement (Xk) to Xi
SHIFT UNIT
20ijk LXi jk Logical shift (Xi) by jk (left shift)
21ijk AXi jk Arithmetic shift (Xi) by jk (right shift)
22ijk LXi Bj, Xk Logical shift (Xk) by (Bj) to Xi
22iji LXi Bj Logical shift (Xi) by (Bj) to Xi
22i0k LXi Xk Transmit (Xk) to Xi
23ijk AXi Bj, Xk Arithmetic shift (Xk) by (Bj) to Xi
23iji AXi Bj Arithmetic shift (Xi) by (Bj) to Xi
23i0k AXi Xk Transmit (Xk) to Xi
24ijk NXi Bj Xk Normalize (Xk) to Xi and Bj
24i0i NXi Normalize (Xi) to Xi
24iji NXi, Bj Normalize (Xi) to Xi and Bj
24i0k NXi Xk Normalize (Xk) to Xi
25ijk ZXi Bj Xk Round and normalize (Xk) to Xi and Bj
25i0i ZXi Round and normalize (Xi) to Xi
25iji ZXi, Bj Round and normalize (Xi) to Xi and Bj
25i0k ZXi Xk Round and normalize (Xk) to Xi
26ijk UXi, Bj Xk Unpack (Xk) to Xi and Bj
26i0i UXi Unpack (Xi) to Xi
26iji UXi, Bj Unpack (Xi) to Xi and Bj
26i0k UXi Xk Unpack (Xk) to Xi
27ijk PXi Xk,Bj Pack (Xk) and (Bj) to Xi
27i0i PXi Pack (Xi) to Xi
27iji PXi Bj Pack (Xi) and (Bj) to Xi
27i0k PXi Xk Pack (Xk) to Xi
ADD UNIT
30ijk FXi Xj+Xk Sum of (Xj) plus (Xk) to Xi
31ijk FXi Xj-Xk Difference of (Xj) minus (Xk) to Xi
32ijk DXi Xj+Xk Double-precision sum of (Xj) plus (Xk) to Xi
33ijk DXi Xj-Xk Double-precision difference of (Xj) minus (Xk) to Xi
34ijk RXi Xj+Xk Rounded sum of (Xj) plus (Xk) to Xi
35ijk RXi Xj-Xk Rounded difference of (Xj) minus (Xk) to Xi
LONG ADD UNIT
36ijk IXi Xj+Xk Integer sum of (Xj) plus (Xk) to Xi
37ijk IXi Xj-Xk Integer difference of (Xj) minus (Xk) to Xi
MULTIPLAY UNIT
40ijk FXi Xj*Xk Product of (Xj) times (Xk) to Xi
41ijk RXi Xj*Xk Rounded product of (Xj) times (Xk) to Xi
42ijk IXi Xj*Xk Integer product of (Xj) times (Xk) to Xi
42ijk DXi Xj*Xk Double-precision product of (Xj) times (Xk) to Xi
43ijk MXi jk Mask of +/-jk bits to Xi
44ijk FXi Xj/Xk Divide(Xj) by (Xk) to Xi
45ijk RXi Xj/Xk Rounded divide (Xj) by (Xk) to Xi
46000 NO No-operation
47ikk CXi Xk Population count of (Xk) to Xi (note)
INCREMENT UNIT
50ijK SAi Aj+K (Aj) plus K to Ai
51ijK SAi Bj+K (Bj) plus K to Ai
51i0K SAi K K to Ai
52ijK SAi Xj+K (Xj) plus K to Ai
53ijk SAi Xj+Bk (Xj) plus (Bk) to Ai
53ij0 SAi Xj (Xj) to Ai
54ijk SAi Aj+Bk (Aj) plus (Bk) to Ai
54ij0 SAi Aj (Aj) to Ai
55ijk SAi Aj-Bk (Aj) minus (Bk) to Ai
56ijk SAi Bj+Bk (Bj) plus (Bk) to Ai
56ij0 SAi Bj (Bj) to Ai
57ijk SAi Bj-Bk (Bj) minus (Bk) to Ai
57i0k SAi -Bk Minus (Bk) to Ai
60ijK SBi Aj+K (Aj) plus K to Bi
61ijK SBi Bj+K (Bj) plus K to Bi
61i0K SBi K K to Bi
62ijK SBi Xj+K (Xj) plus K to Bi
63ijk SBi Xj+Bk (Xj) plus (Bk) to Bi
63ij0 SBi Xj (Xj) to Bi
64ijk SBi Aj+Bk (Aj) plus (Bk) to Bi
64ij0 SBi Aj (Aj) to Bi
65ijk SBi Aj-Bk (Aj) minus (Bk) to Bi
66ijk SBi Bj+Bk (Bj) plus (Bk) to Bi
66ij0 SBi Bj (Bj) to Bi
67ijk SBi Bj-Bk (Bj) minus (Bk) to Bi
67i0k SBi -Bk (Bj) to Bi
70ijK SXi Aj+K (Aj) plus K to Xi
71ijK SXi Bj+K (Bj) plus K to Xi
71i0K SXi K K to Xi
72ijK SXi Xj+K (Xj) plus K to Xi
73ijk SXi Xj+Bk (Xj) plus (Bk) to Xi
73ij0 SXi Xj (Xj) to Xi (18 bit transf!)
74ijk SXi Aj+Bk (Aj) plus (Bk) to Xi
74ij0 SXi Aj (Aj) to Xi
75ijk SXi Aj-Bk (Aj) minus (Bk) to Xi
76ijk SXi Bj+Bk (Bj) plus (Bk) to Xi
76ij0 SXi Bj (Bj) to Xi
77ijk SXi Bj-Bk (Bj) minus (Bk) to Xi
77i0k SXi -Bk (Bj) to Xi
CMU
4640K IM K Move indirect data to word at K
464jK IM Bj+K Move data to word at (Bj)+K
464j0 IM Bj Move data to word at (Bj)
4650K DM K Move direct data to word at K
466 CC & Compare collated
467 CU & Compare un collated
Logical operations
* Logical Product is the boolean AND operation
* Logical addition is the boolean OR operation
* Logical difference is the boolean Exclusive OR (EXOR) operation
En una palabra de 60b caben 4 instrucciones de 15b o 2 instrucciones de 30b. Un programa es una secuencia de palabras con instrucciones. Al ejecutar el programa se obtiene la primera palabra y puede contener 4 instrucciones de 15b o 2 de 30b o combinaciones de 2 de 15b y 1 de 30b. Para los datos usa enteros de Punto Fijo de 60b el bit más a la izquierda representa el signo, 0 positivo y 1 negativo y datos de Punto Flotante en 60 bits en 0-47 la base o coeficiente el bit más a la izquierda es el signo y en 48-59 el exponente el bit más a la izquierda el signo. Para representar caracteres alfanuméricos usa el código display de 6 bits y en una palabra de 60 bits caben 10 caracteres. Dependiendo del código realiza las operaciónes en alguna de las 10 unidades funcionales en paralelo, cuando termina de procesar las instrucciones de la palabra, lee la siguiente palabra con instrucciones, se ejecutan y así continúa hasta la última instrucción del programa.
Para la 6400 tiene los mismos registros, la única diferencia, solo tiene una unidad funcional o mejor dicho una unidad aritmética secuencial o unificada Unified que ejecuta todas las instrucciones anteriores secuencialmente.
El modelo 6500 tiene 2 CPUs 6400 y el modelo 6700 también tiene 2 CPUs una 6600 y una 6400.
Memoria Central CM
La memoria son módulo de núcleos magnéticos de 12 bits de tipo 3D y lectura destructiva, por lo tanto se necesitan 5 módulos para formar una palabra de 60 bits. Tiene una capacidad de 65 Kw o 65 mil palabras o un máximo de 128 Kw.
La memoria es intercalada o interleaved y se organiza en 32 bancos con 5b en la dirección determina que banco usara en memoria y la parte restante de 12b determina la dirección dentro del banco. El acceso para leer o escribir puede ser al mismo tiempo en cada banco.
La memoria central o principal almacena en su parte baja desde la dirección 0, el residente de memoria central CMR del sistema operativo y en la parte alta FBT. En la parte intermedia estan los programas del usuario Prog1, Prog2, Prog3, Prog4... en palabras de 60 bits. Utiliza un circuito piramide para comunicarse con los PPs. La pirámide PYRAMID ensambla palabras de 12 bits de PPs en una palabra de 60 bits de la memoria central y desambla una palabra de 60 bits de memoria central en 5 palabras de 12 bits de PPs.
La memoria son módulo de núcleos magnéticos de 12 bits de tipo 3D y lectura destructiva, por lo tanto se necesitan 5 módulos para formar una palabra de 60 bits. Tiene una capacidad de 65 Kw o 65 mil palabras o un máximo de 128 Kw.
La memoria es intercalada o interleaved y se organiza en 32 bancos con 5b en la dirección determina que banco usara en memoria y la parte restante de 12b determina la dirección dentro del banco. El acceso para leer o escribir puede ser al mismo tiempo en cada banco.
La memoria central o principal almacena en su parte baja desde la dirección 0, el residente de memoria central CMR del sistema operativo y en la parte alta FBT. En la parte intermedia estan los programas del usuario Prog1, Prog2, Prog3, Prog4... en palabras de 60 bits. Utiliza un circuito piramide para comunicarse con los PPs. La pirámide PYRAMID ensambla palabras de 12 bits de PPs en una palabra de 60 bits de la memoria central y desambla una palabra de 60 bits de memoria central en 5 palabras de 12 bits de PPs.
Almacenamiento en Núcleos Extendido ECS
El ECS es una memoria extendida de gran capacidad en incrementos de 500 Kw de palabras w de 60 bits,hasta 4 incrementos de 500 Kw o sea 2000 Kw Es de núcleos magnéticos tipo 2D. Se escribe o lee blocks de 8 palabras de 60 bits y 8 bits de paridad o sea un block de 488 bits. Puede compartirse entre 4 computadoras utilizando un acoplador ECS en las computadoras y el controlador ECS para controlar el acceso y la transferencia de blocks de las computadoras al ECS. Es una primera opción para almacenar gran cantidad de datos a alta velocidad en lugar de usar discos magnéticos.
El ECS es una memoria extendida de gran capacidad en incrementos de 500 Kw de palabras w de 60 bits,hasta 4 incrementos de 500 Kw o sea 2000 Kw Es de núcleos magnéticos tipo 2D. Se escribe o lee blocks de 8 palabras de 60 bits y 8 bits de paridad o sea un block de 488 bits. Puede compartirse entre 4 computadoras utilizando un acoplador ECS en las computadoras y el controlador ECS para controlar el acceso y la transferencia de blocks de las computadoras al ECS. Es una primera opción para almacenar gran cantidad de datos a alta velocidad en lugar de usar discos magnéticos.
Entrada-Salida
Está constituido por 10 unidades de procesamiento periférico PPUs, 12 canales CHs, controladores y dispositivos periféricos.
Está constituido por 10 unidades de procesamiento periférico PPUs, 12 canales CHs, controladores y dispositivos periféricos.
Unidad de Procesadores Periféricos PPUs
Son 10 procesadores periféricos que se mueven en una trayectoria circular de 10 etapas llamado barril BARREL, una etapa se llama tiempo de proceso SLOT TIME cuando un PP pasa, ejecuta sus instrucciones almacenadas en su memoria. Cada PP tiene 4 registros A, P, Q y K. El registro acumulador A de 18 bits, almacena resultados de las operaciones. El contador de programa P de 12 bits, lleva la dirección de la instrucción a ejecutar. El registro Q de 12 bits es de almacenamiento temporal y el registro K de 9 bits conserva el código de operación y lleva la cantidad de vueltas en el barril. Físicamente el barril esta hecho de circuitos para los registros A, P, Q K en cada paso del barril en total hay 10 registros A, P, Q y K formando una trayectoria cerrada, en 1000 nseg dan una vuelta, lo interesante es el valor de los registros que se van desplazando cada 100 nseg en cada paso del barril hasta llegar al SLOT TIME de 100 nseg que tiene circuitos sumadores o incrementadores para cada registro A, P, Q y K y es donde se ejecutan las instrucciones de los PPs. Los formatos de las instrucciones de los PPs son los siguientes.
Formato corto de 12 bits
F(6b)d(6b)
Formato largo de 24 bits
F(6b)d(6b) m(12b)
El formato es de una sola dirección a diferencia de las instrucciones de CPU de 3 direcciones.
El campo F es la función o código de operación, d y m forman la dirección de datos en la memoria del PP. Para accesar su memoria un PP en el paso 6 del ciclo inicia la lectura o escritura y cuando llega al Slot Time la instrucción o dato esta disponible para ejecutarse.
Utilizan el sistema Numérico Octal
0-0, 1-1, 2-2, 3-3, 4-4, 5-5, 6-6, 7-7
10-8, 11-9, 12-10, 13-11, 14-12...
Los números octales facilitan representar las instrucciones y datos binarios del lenguaje de máquina de 0 y 1 que solo entienden los PPs de la CDC6000 para procesar las instrucciones de un programa de PP.
Son 10 procesadores periféricos que se mueven en una trayectoria circular de 10 etapas llamado barril BARREL, una etapa se llama tiempo de proceso SLOT TIME cuando un PP pasa, ejecuta sus instrucciones almacenadas en su memoria. Cada PP tiene 4 registros A, P, Q y K. El registro acumulador A de 18 bits, almacena resultados de las operaciones. El contador de programa P de 12 bits, lleva la dirección de la instrucción a ejecutar. El registro Q de 12 bits es de almacenamiento temporal y el registro K de 9 bits conserva el código de operación y lleva la cantidad de vueltas en el barril. Físicamente el barril esta hecho de circuitos para los registros A, P, Q K en cada paso del barril en total hay 10 registros A, P, Q y K formando una trayectoria cerrada, en 1000 nseg dan una vuelta, lo interesante es el valor de los registros que se van desplazando cada 100 nseg en cada paso del barril hasta llegar al SLOT TIME de 100 nseg que tiene circuitos sumadores o incrementadores para cada registro A, P, Q y K y es donde se ejecutan las instrucciones de los PPs. Los formatos de las instrucciones de los PPs son los siguientes.
Formato corto de 12 bits
F(6b)d(6b)
Formato largo de 24 bits
F(6b)d(6b) m(12b)
El formato es de una sola dirección a diferencia de las instrucciones de CPU de 3 direcciones.
El campo F es la función o código de operación, d y m forman la dirección de datos en la memoria del PP. Para accesar su memoria un PP en el paso 6 del ciclo inicia la lectura o escritura y cuando llega al Slot Time la instrucción o dato esta disponible para ejecutarse.
Utilizan el sistema Numérico Octal
0-0, 1-1, 2-2, 3-3, 4-4, 5-5, 6-6, 7-7
10-8, 11-9, 12-10, 13-11, 14-12...
Los números octales facilitan representar las instrucciones y datos binarios del lenguaje de máquina de 0 y 1 que solo entienden los PPs de la CDC6000 para procesar las instrucciones de un programa de PP.
INSTRUCCIONES DE PPs
Operación Instruc Descripción Cycle
0000 Pass Pass 1c
01d m LJM m,d Long jump to address m+(d) 3c
02d m RJM m,d Return jump to address dm
(m+(d))= P+2; P=m+(d)+1 4
PPMem
3000-0200 Realiza rutina
3001-2400
3002
...
2400-0100 Salta a continuar prog
2401-3002
2402
...
2405
2406-0371 Regresa 6 posiciones
Operación Instruc Descripción Cycle
0000 Pass Pass 1c
01d m LJM m,d Long jump to address m+(d) 3c
02d m RJM m,d Return jump to address dm
(m+(d))= P+2; P=m+(d)+1 4
PPMem
3000-0200 Realiza rutina
3001-2400
3002
...
2400-0100 Salta a continuar prog
2401-3002
2402
...
2405
2406-0371 Regresa 6 posiciones
03r UJN r Unconditional relative (fwd/bkwd) jump to P+r P-r 1c
04r ZJN r Relative jump (A)=0 1c
05r NJN r Relative jump (A)<>0 1c
06r PJN r Relative jump (A) >= 0 1c
07r MJN r Relative jump (A)< 0 1c
NO ADDRESS
10r SHN r Shift left circular (+r) or right end-off (-r) 1
11d LMN d Logical difference (A)-d to A 1c
12d LPN d Logical product (A)*d to A 1c
13d SCN d Selective clear each d bit set in A to A 1c
14d LDN d Load d to A 1c
15d LCN d Load complement d to A 1c
16d ADN d Add (A)+d to A 1c
17d SBN d Subtract (A)-d to A 1c
20d m LDC dm Load constant dm to A 2c
21d m ADC dm Add constant dm+(A) to A 2c
22d m LPC dm Logical product constant dm*(A) to A 2c
23d m LMC dm Logical difference (A)-constant dm to A 2c
CPU
2400 PSN Pass (no-op) 3c
2500 PSN Pass (no-op) 3c
260d EXN d Exchange jump CPU d unconditional to (A) 2c
El contenido del registro A del PP se trasfiere al CPU d y una señal para que inicie el mecanismo de un EXJ de parar el programa en ejecución guardar en su paquete EXJ el valor de los registros A, B, X, RA, FL y PC y con la dirección del registro A del PP va al paquete del nuevo programa y cargar los valores en A, B, X y PC y continuar su ejecución.
261d Monitor Exchange Jump Is optional in conjuction with the Central Exchange Jump CEJ 2c
Funciona igual que EXN pero checa la bandera de Flag Monitor si esta inactiva se ejecuta la instrucción y activa la bandera o Flag Monitor indicando que el CPU esta en estado de monitor.
270d RPN d Read program address CPU d to A 1
DIRECT ADDRESS
30d LDD d Load (d) to A 2c
31d ADD d Add (A)+(d) to A 2c
32d SBD d Subtract (A)-(d) to A 2c
33d LMD d Logical difference (A)-(d) to A 2c
34d STD d Store (A) to d 2c
35d RAD d Replace add (d)+(A) to A and d 4c
36d AOD d Replace add one (d)+1 to A and d 5c
37d SOD d Replace substract one (d)-1 to A and d 5c
INDIRECT ADDRESS
40d LDI d Load ((d)) to A 3c
41d ADI d Add (A)+((d)) to A 3c
42d SBI d Subtract (A)-((d)) to A 3c
43d LMI d Logical difference (A)-((d)) to A 3c
44d STI d Store (A) to (d) 3c
45d RAI d Replace add ((d))+(A) to A and (d) 5c
46d AOI d Replace add one ((d))+1 to A and (d) 6c
47d SOI d Replace substract one ((d))-1 to A and (d) 6c
INDEX ADDRESS
50d LDM m,d Load (m+(d)) to A 4c
51d ADM m,d Add (A)+(m+(d)) to A 4c
52d SBM m,d Subtract (A)-(m+(d)) to A 4c
53d LMM m,d Logical difference (A)-(m+(d)) to A 4c
54d STM m,d Store (A) to m+(d) 4c
55d RAM m,d Replace add (m+(d))+(A) to A and m+(d) 6c
56d AOM m,d Replace add one (m+(d))+1 to A and m+(d) 7c
57d SOM m,d Replace substract one (m+(d))-1 to A and m+(d) 7c
CENTRAL MEMORY
60d CRD d Central read from (A) to d (up to d+4) 12c
61d m CRM d Central read (d) words from (A) to m (up to m+d-1) 7+(d)*5c
62d CWD d Central write from d (up to d+4) to (A) 6c
63d m CWM m,d Central write (d) words from m to (A) up to (A)+(d)-1 6+(d)*5c
IO CHANNELS
64d m AJM m,d Jump to m if channel d is active
65d m IJM m,d Jump to m if channel d is inactive 2c
66d m FJM m,d Jump to m if channel d is full 2c
67d m EJM m,d Jump to m if channel d is empty 2c
70d IAN d Input from channel d to A 2c
71d m IAM m,d Input (A) words from channel d to m min. 5+(A)*1c
72d OAN d Output (A) to channel d 2c
73d m OAM d Output (A) words on channel d from m min. 5+(A)*1c
74d ACN d Activate channel d 2c
75d DCN d Disconnect channel d 2c
76d FAN d Function (A) on channel d 2c
77d m FNC m,d Function m on channel d 2c
Un programa de PP es una secuencia de instrucciones de palabras de 12 bits almacenados en la memoria del PP. Las instrucciones son de una palabra o dos palabras. Cuando se inicia el programa se obtiene la primera instrucción, si es de una palabra identifica el código de operación y se ejecuta. Si es de 2 palabras hace otro ciclo de memoria para obtener el dato o la dirección del dato en memoria y se ejecuta la instrucción, así continúa hasta la última instrucción del programa.
04r ZJN r Relative jump (A)=0 1c
05r NJN r Relative jump (A)<>0 1c
06r PJN r Relative jump (A) >= 0 1c
07r MJN r Relative jump (A)< 0 1c
NO ADDRESS
10r SHN r Shift left circular (+r) or right end-off (-r) 1
11d LMN d Logical difference (A)-d to A 1c
12d LPN d Logical product (A)*d to A 1c
13d SCN d Selective clear each d bit set in A to A 1c
14d LDN d Load d to A 1c
15d LCN d Load complement d to A 1c
16d ADN d Add (A)+d to A 1c
17d SBN d Subtract (A)-d to A 1c
20d m LDC dm Load constant dm to A 2c
21d m ADC dm Add constant dm+(A) to A 2c
22d m LPC dm Logical product constant dm*(A) to A 2c
23d m LMC dm Logical difference (A)-constant dm to A 2c
CPU
2400 PSN Pass (no-op) 3c
2500 PSN Pass (no-op) 3c
260d EXN d Exchange jump CPU d unconditional to (A) 2c
El contenido del registro A del PP se trasfiere al CPU d y una señal para que inicie el mecanismo de un EXJ de parar el programa en ejecución guardar en su paquete EXJ el valor de los registros A, B, X, RA, FL y PC y con la dirección del registro A del PP va al paquete del nuevo programa y cargar los valores en A, B, X y PC y continuar su ejecución.
261d Monitor Exchange Jump Is optional in conjuction with the Central Exchange Jump CEJ 2c
Funciona igual que EXN pero checa la bandera de Flag Monitor si esta inactiva se ejecuta la instrucción y activa la bandera o Flag Monitor indicando que el CPU esta en estado de monitor.
270d RPN d Read program address CPU d to A 1
DIRECT ADDRESS
30d LDD d Load (d) to A 2c
31d ADD d Add (A)+(d) to A 2c
32d SBD d Subtract (A)-(d) to A 2c
33d LMD d Logical difference (A)-(d) to A 2c
34d STD d Store (A) to d 2c
35d RAD d Replace add (d)+(A) to A and d 4c
36d AOD d Replace add one (d)+1 to A and d 5c
37d SOD d Replace substract one (d)-1 to A and d 5c
INDIRECT ADDRESS
40d LDI d Load ((d)) to A 3c
41d ADI d Add (A)+((d)) to A 3c
42d SBI d Subtract (A)-((d)) to A 3c
43d LMI d Logical difference (A)-((d)) to A 3c
44d STI d Store (A) to (d) 3c
45d RAI d Replace add ((d))+(A) to A and (d) 5c
46d AOI d Replace add one ((d))+1 to A and (d) 6c
47d SOI d Replace substract one ((d))-1 to A and (d) 6c
INDEX ADDRESS
50d LDM m,d Load (m+(d)) to A 4c
51d ADM m,d Add (A)+(m+(d)) to A 4c
52d SBM m,d Subtract (A)-(m+(d)) to A 4c
53d LMM m,d Logical difference (A)-(m+(d)) to A 4c
54d STM m,d Store (A) to m+(d) 4c
55d RAM m,d Replace add (m+(d))+(A) to A and m+(d) 6c
56d AOM m,d Replace add one (m+(d))+1 to A and m+(d) 7c
57d SOM m,d Replace substract one (m+(d))-1 to A and m+(d) 7c
CENTRAL MEMORY
60d CRD d Central read from (A) to d (up to d+4) 12c
61d m CRM d Central read (d) words from (A) to m (up to m+d-1) 7+(d)*5c
62d CWD d Central write from d (up to d+4) to (A) 6c
63d m CWM m,d Central write (d) words from m to (A) up to (A)+(d)-1 6+(d)*5c
IO CHANNELS
64d m AJM m,d Jump to m if channel d is active
65d m IJM m,d Jump to m if channel d is inactive 2c
66d m FJM m,d Jump to m if channel d is full 2c
67d m EJM m,d Jump to m if channel d is empty 2c
70d IAN d Input from channel d to A 2c
71d m IAM m,d Input (A) words from channel d to m min. 5+(A)*1c
72d OAN d Output (A) to channel d 2c
73d m OAM d Output (A) words on channel d from m min. 5+(A)*1c
74d ACN d Activate channel d 2c
75d DCN d Disconnect channel d 2c
76d FAN d Function (A) on channel d 2c
77d m FNC m,d Function m on channel d 2c
Un programa de PP es una secuencia de instrucciones de palabras de 12 bits almacenados en la memoria del PP. Las instrucciones son de una palabra o dos palabras. Cuando se inicia el programa se obtiene la primera instrucción, si es de una palabra identifica el código de operación y se ejecuta. Si es de 2 palabras hace otro ciclo de memoria para obtener el dato o la dirección del dato en memoria y se ejecuta la instrucción, así continúa hasta la última instrucción del programa.
Memoria de Procesadores Periféricos PPM
Cada PP tiene una memoria de un módulo de 4 Kw la palabra w de 12 bits, donde almacena las instrucciones y datos de los programas de PPs. Las memorias son de núcleos magnéticos de organización 3D de lectura destructiva. Para accesar la memoria el PP en el paso 6 inicia el ciclo de memoria y cuando llega al Slot Time la instrucción o datos esta disponible para ejecutarse. Algunas instrucciones de PP se comunican con los equipos periféricos utilizando los canales CHs y controladores, también con la memoria central usando la pirámide. En la memoria de cada PP se cargan programas del sistema operativo en PP0 monitor MTR que controla a todo el sistema y permite comunicarse a los otros PPs usando un área de comunicación en CMR. En los demás PPs se carga un programa residente PPR que permite comunicarse con MTR también usando el área de comunicación de CMR. También en un PP se carga y utiliza de forma permanente el programa Dynamic System Display DSD para atender y operar la consola.
Cada PP tiene una memoria de un módulo de 4 Kw la palabra w de 12 bits, donde almacena las instrucciones y datos de los programas de PPs. Las memorias son de núcleos magnéticos de organización 3D de lectura destructiva. Para accesar la memoria el PP en el paso 6 inicia el ciclo de memoria y cuando llega al Slot Time la instrucción o datos esta disponible para ejecutarse. Algunas instrucciones de PP se comunican con los equipos periféricos utilizando los canales CHs y controladores, también con la memoria central usando la pirámide. En la memoria de cada PP se cargan programas del sistema operativo en PP0 monitor MTR que controla a todo el sistema y permite comunicarse a los otros PPs usando un área de comunicación en CMR. En los demás PPs se carga un programa residente PPR que permite comunicarse con MTR también usando el área de comunicación de CMR. También en un PP se carga y utiliza de forma permanente el programa Dynamic System Display DSD para atender y operar la consola.
Canales CHs
Hay 12 canales con sus registros de canal para comunicarse los PPs y los equipos periféricos por medio de sus controladores. Hay instrucciones de PP para manipular los canales y prepararlos para la comunicación. Cualquier PP puede usar cualquier canal dando gran versatilidad a las instrucciones de entrada-salida de los PPs. Es de especial interés decir que al canal 0 está conectado al panel de DesdStart que inicia la carga del sistema operativo, pero también se puede conectar a otro controlador y equipo. El canal 14 tiene conectado el real time clock o reloj de tiempo real que da el tiempo al sistema. En los canales restantes se conectan los controladores y sus correspodientes equipos periféricos.
Hay 12 canales con sus registros de canal para comunicarse los PPs y los equipos periféricos por medio de sus controladores. Hay instrucciones de PP para manipular los canales y prepararlos para la comunicación. Cualquier PP puede usar cualquier canal dando gran versatilidad a las instrucciones de entrada-salida de los PPs. Es de especial interés decir que al canal 0 está conectado al panel de DesdStart que inicia la carga del sistema operativo, pero también se puede conectar a otro controlador y equipo. El canal 14 tiene conectado el real time clock o reloj de tiempo real que da el tiempo al sistema. En los canales restantes se conectan los controladores y sus correspodientes equipos periféricos.
Controladores y Equipos Periféricos
Un controlador en general permite controlar y asignar un buffer de memoria a cada uno de los periféricos del mismo tipo, hacen conversiones de códigos y se pueden conectar a un canal o hasta 2 canales. Cada equipo periférico tiene características propias del medio que esta utilizando para grabar y recuperar los datos, como tarjetas perforadas, cintas y discos magnéticos, la introducción y despliegue de los datos de forma directa en la consola de operación o de terminales locales y remotas, utilizando líneas de comunicación.

Un controlador en general permite controlar y asignar un buffer de memoria a cada uno de los periféricos del mismo tipo, hacen conversiones de códigos y se pueden conectar a un canal o hasta 2 canales. Cada equipo periférico tiene características propias del medio que esta utilizando para grabar y recuperar los datos, como tarjetas perforadas, cintas y discos magnéticos, la introducción y despliegue de los datos de forma directa en la consola de operación o de terminales locales y remotas, utilizando líneas de comunicación.

Panel DeadStart DS
El panel DS tiene una matrix de 12 filas de 12 switchs cada uno, hacia arriba reprenta un 1 y hacia abajo un 0. En está matrix se pone una instrucción de PP de 12 bits en cada fila, las 12 filas representan un programa de PP, al mover el switch de Dead Start ejecuta el programa PP0 y va a leer el sistema operativo o los diagnósticos de mantenimiento de una cinta o disco magnético. Para el sistema operativo en PP0 se carga monitor MTR y en los otros, el programa procesador de periférico residente PPR y en memoria central queda el programa residente de memoria CMR.

El panel DS tiene una matrix de 12 filas de 12 switchs cada uno, hacia arriba reprenta un 1 y hacia abajo un 0. En está matrix se pone una instrucción de PP de 12 bits en cada fila, las 12 filas representan un programa de PP, al mover el switch de Dead Start ejecuta el programa PP0 y va a leer el sistema operativo o los diagnósticos de mantenimiento de una cinta o disco magnético. Para el sistema operativo en PP0 se carga monitor MTR y en los otros, el programa procesador de periférico residente PPR y en memoria central queda el programa residente de memoria CMR.

Unidades de Discos Magnéticos DU
Las unidades de discos magnéticos 844, estan conectados a un controlador 7054 y pueden conectarse hasta 8 unidades y el controlador se puede conectar a uno o dos canales. El controlador contiene un pequeño procesador programable con una memoria buffer de1kw de palabras de 12b, controla y asigna una área a cada unidad para comunicarse de forma independiente entre los PPs, CHs y las unidades de disco. Cada unidad tiene un paquete de disco 881 de 118 millones de caracteres de 6 bits (238) es removible, puede quitarse y ponerse en la unidad, tienen un conjunto de 21 placas redondas de discos con una capa de material magnético, la superior e inferior no se usa y una sirve de control, en las 19 restantes se escribe y leen los datos. Cada paquete de disco magnéticos contiene varios discos sobre puestos en un eje, acoplados a un motor que giran a 3600 rpm. La unidad 844 tiene un ensamble de 20 cabezas de escritura y lectura, solo se puede escribir o leer un sector de 640 caracteres. Usa la Modulación de Frecuencia Modificada o Modified Frecuency Modulation MFM para grabar y leer. La cabeza de escritura tiene un cable delgado enredado en un pequeño imán que va al circuito de escritura, al circular corriente la cabeza induce un campo magnético en la superficie del disco y polariza en un sentido las partículas magnéticas grabando un 1 y en sentido contrario un 0, para cada bit de un caracter hasta completar los 640 caracteres de un sector. La cabeza de lectura tiene un cable delgado que enreda un pequeño imán que va a un circuito de lectura, cuando se activa la lectura detecta las polarizaciones de 1 y 0 de la superficie del disco y lee bit por bit cada caracter hasta leer los 640 caracteres del sector.
El ensamble de cabezas de escritura y lectura es movible sobre una pista, debido a su eje deslizable enredado por conductores planos Voice Coil que van a un circuito de movimiento y se mueve dentro de un campo magnético muy fuerte creado por un imán fijo, dependiendo de la intensidad de la corriente y dirección de la corriente el ensamble de cabezas se mueve en ambas direcciones primero lentamente acelera y luego desaceleran hasta pararse. Las cabezas se mueven entre los discos desde el track más externo al track más interno. Para leer o escribir datos en los discos, están organizados como 411 cilindros y 19 tracks por cilindro, cada track contiene 26 sectores con 640 caracteres cada sector. Para leer o escribir se necesita el cilindro, track y sector, entonces internamente se calcula para ir de su poción actual a la deseada, primer inician lentamente, acelera y cuando se acerca desacelera y para en el cilndro deseado, haciendo un tiempo seek time promedio de 30 mseg. se selecciona la cabeza del track, ahora espera el sector este bajo la cabeza en un tiempo, latency time de 8 mseg, cuando llega al sector deseado se energiza la cabeza. Para escribir el circuito de escritura crea una corriente en un sentido y genera una campo magnético que polariza la superficie del disco en un sentido grava un 1, al cambiar la dirección de la corriente se escribe un 0 para un solo bit, así continúa con cada bit de un caracter hasta completarse los 640 caracteres del sector. Para leer el circuito de lectura detecta cambios de polaridad de 1 y 0 para cada bit de un carácter, así continúa con los 640 caracteres del sector. Para escritura y lectura transfiere los datos desde un PP para escritura y a un PP para lectura. En un interlace 1:1 a 0.92 millones de caracteres por seg. en un interlace 2:1 a 0.64 millones de caracteres por seg. En un interlace 1:1 los sectores en una vuelta se leen secuencialmente. En un interlace 2:1 primero en una vuelta se lee los sectores pares y en otra vuelta se leen los impares.
Una cabeza y track de control llamado servotrack controlan el movimiento del ensamble de cabezas y por lo tanto el acceso de las otras 19 cabezas a los cilindros, tracks y sectores.
Los archivo que se almacena en el disco esta constituido por registro de longitud fija o variable. Varios registros puede estar en un sector o un registro puede ocupar varios sectores de datos. A diferencia de las cintas magnéticas que son secuenciales, los discos magnéticos pueden ser secuenciales y random, es decir pueden ir a cualquier sector del disco. Así tenemos archivos de acceso secuencial y directo, con estas funciones se tienen la capacidad de crear bases de datos. Cuando un trabajo o job de un usuario requiere archivos, en la consola aparecen los mensajes, pero son asignados automáticamente por el sistema operativo, es responsabilidad del usuario llamar los archivos correctos para continuar su procesamiento.

Las unidades de discos magnéticos 844, estan conectados a un controlador 7054 y pueden conectarse hasta 8 unidades y el controlador se puede conectar a uno o dos canales. El controlador contiene un pequeño procesador programable con una memoria buffer de1kw de palabras de 12b, controla y asigna una área a cada unidad para comunicarse de forma independiente entre los PPs, CHs y las unidades de disco. Cada unidad tiene un paquete de disco 881 de 118 millones de caracteres de 6 bits (238) es removible, puede quitarse y ponerse en la unidad, tienen un conjunto de 21 placas redondas de discos con una capa de material magnético, la superior e inferior no se usa y una sirve de control, en las 19 restantes se escribe y leen los datos. Cada paquete de disco magnéticos contiene varios discos sobre puestos en un eje, acoplados a un motor que giran a 3600 rpm. La unidad 844 tiene un ensamble de 20 cabezas de escritura y lectura, solo se puede escribir o leer un sector de 640 caracteres. Usa la Modulación de Frecuencia Modificada o Modified Frecuency Modulation MFM para grabar y leer. La cabeza de escritura tiene un cable delgado enredado en un pequeño imán que va al circuito de escritura, al circular corriente la cabeza induce un campo magnético en la superficie del disco y polariza en un sentido las partículas magnéticas grabando un 1 y en sentido contrario un 0, para cada bit de un caracter hasta completar los 640 caracteres de un sector. La cabeza de lectura tiene un cable delgado que enreda un pequeño imán que va a un circuito de lectura, cuando se activa la lectura detecta las polarizaciones de 1 y 0 de la superficie del disco y lee bit por bit cada caracter hasta leer los 640 caracteres del sector.
El ensamble de cabezas de escritura y lectura es movible sobre una pista, debido a su eje deslizable enredado por conductores planos Voice Coil que van a un circuito de movimiento y se mueve dentro de un campo magnético muy fuerte creado por un imán fijo, dependiendo de la intensidad de la corriente y dirección de la corriente el ensamble de cabezas se mueve en ambas direcciones primero lentamente acelera y luego desaceleran hasta pararse. Las cabezas se mueven entre los discos desde el track más externo al track más interno. Para leer o escribir datos en los discos, están organizados como 411 cilindros y 19 tracks por cilindro, cada track contiene 26 sectores con 640 caracteres cada sector. Para leer o escribir se necesita el cilindro, track y sector, entonces internamente se calcula para ir de su poción actual a la deseada, primer inician lentamente, acelera y cuando se acerca desacelera y para en el cilndro deseado, haciendo un tiempo seek time promedio de 30 mseg. se selecciona la cabeza del track, ahora espera el sector este bajo la cabeza en un tiempo, latency time de 8 mseg, cuando llega al sector deseado se energiza la cabeza. Para escribir el circuito de escritura crea una corriente en un sentido y genera una campo magnético que polariza la superficie del disco en un sentido grava un 1, al cambiar la dirección de la corriente se escribe un 0 para un solo bit, así continúa con cada bit de un caracter hasta completarse los 640 caracteres del sector. Para leer el circuito de lectura detecta cambios de polaridad de 1 y 0 para cada bit de un carácter, así continúa con los 640 caracteres del sector. Para escritura y lectura transfiere los datos desde un PP para escritura y a un PP para lectura. En un interlace 1:1 a 0.92 millones de caracteres por seg. en un interlace 2:1 a 0.64 millones de caracteres por seg. En un interlace 1:1 los sectores en una vuelta se leen secuencialmente. En un interlace 2:1 primero en una vuelta se lee los sectores pares y en otra vuelta se leen los impares.
Una cabeza y track de control llamado servotrack controlan el movimiento del ensamble de cabezas y por lo tanto el acceso de las otras 19 cabezas a los cilindros, tracks y sectores.
Los archivo que se almacena en el disco esta constituido por registro de longitud fija o variable. Varios registros puede estar en un sector o un registro puede ocupar varios sectores de datos. A diferencia de las cintas magnéticas que son secuenciales, los discos magnéticos pueden ser secuenciales y random, es decir pueden ir a cualquier sector del disco. Así tenemos archivos de acceso secuencial y directo, con estas funciones se tienen la capacidad de crear bases de datos. Cuando un trabajo o job de un usuario requiere archivos, en la consola aparecen los mensajes, pero son asignados automáticamente por el sistema operativo, es responsabilidad del usuario llamar los archivos correctos para continuar su procesamiento.
Consola de Operación
La consola de operación DD60 esta conectada a su controlador y tiene dos tubos de rayos cátodicos TRC redondos de 12" izquierdo y derecho, cada uno tiene un cuadrado de 10" dividido en una matrix de 512x512 posiciones donde se pueden desplegar caracteres y gráficos. En modo de caracteres despliega por línea 16 caracteres grandes, 32 medianos o 64 pequeños. En la condola se ve la actividad de todo el sistema operativo con varias pantallas que despliegan información, utiliza el Display Code de 6 bits. El teclado tiene 48 teclas de caracteres alfanúmericos, por donde se introduce comandos, usa dos letras de la pantalla que desea verse, IzquieraDerecha. Si tecleamos AB. la pantalla izquierda A despliega un dayfile que va registrando toda las actividades y se va grabando en un archivo Dayfile y la pantalla principal B despliega los puntos de control donde se estan ejecutando los programas como Prog1-4 y se puede ver el estado de cada programa si esta ejecutandose o en estado de espera por datos, y otra información. C y D despliega la actividad de memoria. E el estado del equipo y hay otras pantallas.


La consola de operación DD60 esta conectada a su controlador y tiene dos tubos de rayos cátodicos TRC redondos de 12" izquierdo y derecho, cada uno tiene un cuadrado de 10" dividido en una matrix de 512x512 posiciones donde se pueden desplegar caracteres y gráficos. En modo de caracteres despliega por línea 16 caracteres grandes, 32 medianos o 64 pequeños. En la condola se ve la actividad de todo el sistema operativo con varias pantallas que despliegan información, utiliza el Display Code de 6 bits. El teclado tiene 48 teclas de caracteres alfanúmericos, por donde se introduce comandos, usa dos letras de la pantalla que desea verse, IzquieraDerecha. Si tecleamos AB. la pantalla izquierda A despliega un dayfile que va registrando toda las actividades y se va grabando en un archivo Dayfile y la pantalla principal B despliega los puntos de control donde se estan ejecutando los programas como Prog1-4 y se puede ver el estado de cada programa si esta ejecutandose o en estado de espera por datos, y otra información. C y D despliega la actividad de memoria. E el estado del equipo y hay otras pantallas.


Terminales Locales y Remotas
Los dispositivos terminales son de entrada y salida, están conectados al controlador de comunicaciones o Data Set Controller DSC 6671 y este a un canal, soporta hasta 16 terminales, desde 110 hasta 9600 bps en modo TeletypeDataSet ATT103 o Dataphone Data Set 201A/B en half o full duplex. Todas son controladas por el programa INTERCOM. El DSC tiene una memoria de 64 palabras de 27 bits, una área de 4 palabras era asignada a cada terminal para comunicarse entre los PPs, CHs y las terminales. El programa recorre el área asignada a cada terminal para enviar o recibir datos de las terminales. El DSC por lo anterior también tiene el nombre de Multiplexor de comunicaciones MUX por ir recorriendo cada una de las 16 terminales y atenderlas. Las terminales usan el código ascii y dan la opción de trabajar en forma interactiva. A diferencia del sistema operativo batch, el usuario interactúa directamente con la computadora surgiendo así los sistemas operativos de tiempo compartido o multiusuario. Hay terminales locales y remotas. Las 713, 714, 721,751 y 756 usan cables RS232 para conectarse, cada terminal tiene un teclado y pantalla y de forma interactiva el usuario introduce por el teclado programas y datos, casi inmediatamente obtiene sus resultados en la pantalla. En la terminal se introduce carácter por carácter y se despleiga en la pantalla, así se continua hasta formar palabras o comandos o varias palabras hasta un máximo y entonces se envía el block completo.
Las terminales remotas UT200, 731-32-34 se conectan a un modem y este a una línea telefónica y en la localidad remota hay otro modem y este se conecta a la terminal remota batch, está tiene una consola de operación, un lectora y perforadora de tarjeta y una impresora. El batch de tarjetas que tiene un programa y datos, son enviados al computador central para procesarse y los resultados obtenidos se regresan a imprimirse.
En la consola de operación se puede observar los trabajos de las terminales locales y remotas, controladas por INTERCOM, para iniciar su operación las terminales requieren una identificación LOGIN para entrar al sistema.

Los dispositivos terminales son de entrada y salida, están conectados al controlador de comunicaciones o Data Set Controller DSC 6671 y este a un canal, soporta hasta 16 terminales, desde 110 hasta 9600 bps en modo TeletypeDataSet ATT103 o Dataphone Data Set 201A/B en half o full duplex. Todas son controladas por el programa INTERCOM. El DSC tiene una memoria de 64 palabras de 27 bits, una área de 4 palabras era asignada a cada terminal para comunicarse entre los PPs, CHs y las terminales. El programa recorre el área asignada a cada terminal para enviar o recibir datos de las terminales. El DSC por lo anterior también tiene el nombre de Multiplexor de comunicaciones MUX por ir recorriendo cada una de las 16 terminales y atenderlas. Las terminales usan el código ascii y dan la opción de trabajar en forma interactiva. A diferencia del sistema operativo batch, el usuario interactúa directamente con la computadora surgiendo así los sistemas operativos de tiempo compartido o multiusuario. Hay terminales locales y remotas. Las 713, 714, 721,751 y 756 usan cables RS232 para conectarse, cada terminal tiene un teclado y pantalla y de forma interactiva el usuario introduce por el teclado programas y datos, casi inmediatamente obtiene sus resultados en la pantalla. En la terminal se introduce carácter por carácter y se despleiga en la pantalla, así se continua hasta formar palabras o comandos o varias palabras hasta un máximo y entonces se envía el block completo.
Las terminales remotas UT200, 731-32-34 se conectan a un modem y este a una línea telefónica y en la localidad remota hay otro modem y este se conecta a la terminal remota batch, está tiene una consola de operación, un lectora y perforadora de tarjeta y una impresora. El batch de tarjetas que tiene un programa y datos, son enviados al computador central para procesarse y los resultados obtenidos se regresan a imprimirse.
En la consola de operación se puede observar los trabajos de las terminales locales y remotas, controladas por INTERCOM, para iniciar su operación las terminales requieren una identificación LOGIN para entrar al sistema.

Unidades de Cinta Magnética
El controlador de cintas 7021 se puede conectar a dos canales y se conectan hasta 8 unidades de cintas. El controlador contiene un pequeño procesador programable con una memoria buffer de1kw de palabras de 12b, controla y asigna una área a cada unidad para comunicarse de forma independiente entre los PPs, CHs y las unidades de cinta. Las unidades de cinta magnética son la 677 para grabar y leer 7 canales en NRZI y código BCD y la unidad de cinta 679 de 9 canales de datos en Phase Encode PE y Group Code Recording GCR en código ABCDIC.
El ensamble de escritura lectura tiene 7 o 9 cabezas en la parte baja tiene un pequeño espacio o gap en cada una de ellas donde se forma el campo magnético que afecta a la cinta que pasa debajo de las cabezas para escribir o leer. El gap separa la parte de escritura y lectura, la parte de escritura del lado izquierdo tiene un pequeño cable enredado en un imán que va a los circuitos de escritura y la parte de lectura del lado izquierdo también tiene un pequeño cable enredado en un imán que va a los circuitos de lectura. Al energizar los cables con una corriente crean un campo magnético en el gap y afecta a la cinta que pasa debajo de ellas. Para escritura la corriente que circula por el circuito de escritura polariza en un sentido los bits 1 y en el sentido opuesto los bits 0 de la cinta magnética que pasa debajo de las cabezas. Para leer, se energiza el circuito de lectura, las cabezas detectan los cambios de la polarización de los bits 1 y 0 de la cinta que pasa debajo de ellas.
Los carretes de cinta grandes miden 2400 ft de 0.5" de ancho y pueden almacenar 250,000 tarjetas. Otra característica de las cintas magnéticas es su densidad, hay de 800 y 1200 bpi bytes por pulgada. La unidad de cinta tienen 2 carretes giratorios, un izquierdo y otro derecho, en el derecho se coloca un carrete de cinta y la punta de la cinta se pasa por encima de la columna de vacio derecho y se pasa debajo del ensamble de cabezas y por encima de la columna de vacio izquierdo, se enreda la punta de la cinta en el carrete giratorio izquierdo, al presionar LOAD empiezan a girar los carretes y las columnas de vacio jalan la cinta y por medio de fotodiodos sensores en la columna de vació controlan el movimiento de los carretes giratorios y además se adhiere a un capstan en la salida izquierda de la columna, que también se mueven y absorbe la cinta con el fin de controlar el movimiento de la cinta sin dañarla y quede tensionada al pasar bajo el ensamble de cabezas. Los carretes siguen girando hasta que detecta la marca de inicio reflectiva y para su movimiento. Al presionar READY la unidad esta lista para recibir comandos de escritura y lectura e iniciar el movimiento de la cinta y ser controlado por los fotodiodos sensores de las dos columnas de vació y también energizar las cabezas para la escritura o lectura de datos en la cinta magnética. El movimento de la cinta para entre registros separados por un interrecord gap IRG de 0.75" e inicia el movimiento a una velocidad de 112 IPS esto es posible debido a la cinta acumulada en las columnas de vació y al IRG, así continúa hasta el fin del archivo o el fin de carrete. Los datos se organizan como archivos que contiene varios registros de longitud fija o variable, separados por un espacio de 0.75" el IRG. Los datos se graban y leen secuencialmente en las cintas. Si tenemos un archivo de 1000 registros de 80 caracteres habrá espacio desperdiciado por los IRG. Para solucionar podemos crear blocks de 10 registros entonces el espacio desperdiciado será menor.
Cuando un trabajo o job de un usuario requiere unidades de cinta, en la consola aparece los mensajes, el operador coloca los carretes de cinta y las asigna al job para continuar su procesamiento.
De gran importancia cabe mencionar el uso de las cintas para hacer respaldos de datos almacenados en los discos magnéticos, previniendo fallas en los discos y con los respaldos se pueden recuperar los datos.

El controlador de cintas 7021 se puede conectar a dos canales y se conectan hasta 8 unidades de cintas. El controlador contiene un pequeño procesador programable con una memoria buffer de1kw de palabras de 12b, controla y asigna una área a cada unidad para comunicarse de forma independiente entre los PPs, CHs y las unidades de cinta. Las unidades de cinta magnética son la 677 para grabar y leer 7 canales en NRZI y código BCD y la unidad de cinta 679 de 9 canales de datos en Phase Encode PE y Group Code Recording GCR en código ABCDIC.
El ensamble de escritura lectura tiene 7 o 9 cabezas en la parte baja tiene un pequeño espacio o gap en cada una de ellas donde se forma el campo magnético que afecta a la cinta que pasa debajo de las cabezas para escribir o leer. El gap separa la parte de escritura y lectura, la parte de escritura del lado izquierdo tiene un pequeño cable enredado en un imán que va a los circuitos de escritura y la parte de lectura del lado izquierdo también tiene un pequeño cable enredado en un imán que va a los circuitos de lectura. Al energizar los cables con una corriente crean un campo magnético en el gap y afecta a la cinta que pasa debajo de ellas. Para escritura la corriente que circula por el circuito de escritura polariza en un sentido los bits 1 y en el sentido opuesto los bits 0 de la cinta magnética que pasa debajo de las cabezas. Para leer, se energiza el circuito de lectura, las cabezas detectan los cambios de la polarización de los bits 1 y 0 de la cinta que pasa debajo de ellas.
Los carretes de cinta grandes miden 2400 ft de 0.5" de ancho y pueden almacenar 250,000 tarjetas. Otra característica de las cintas magnéticas es su densidad, hay de 800 y 1200 bpi bytes por pulgada. La unidad de cinta tienen 2 carretes giratorios, un izquierdo y otro derecho, en el derecho se coloca un carrete de cinta y la punta de la cinta se pasa por encima de la columna de vacio derecho y se pasa debajo del ensamble de cabezas y por encima de la columna de vacio izquierdo, se enreda la punta de la cinta en el carrete giratorio izquierdo, al presionar LOAD empiezan a girar los carretes y las columnas de vacio jalan la cinta y por medio de fotodiodos sensores en la columna de vació controlan el movimiento de los carretes giratorios y además se adhiere a un capstan en la salida izquierda de la columna, que también se mueven y absorbe la cinta con el fin de controlar el movimiento de la cinta sin dañarla y quede tensionada al pasar bajo el ensamble de cabezas. Los carretes siguen girando hasta que detecta la marca de inicio reflectiva y para su movimiento. Al presionar READY la unidad esta lista para recibir comandos de escritura y lectura e iniciar el movimiento de la cinta y ser controlado por los fotodiodos sensores de las dos columnas de vació y también energizar las cabezas para la escritura o lectura de datos en la cinta magnética. El movimento de la cinta para entre registros separados por un interrecord gap IRG de 0.75" e inicia el movimiento a una velocidad de 112 IPS esto es posible debido a la cinta acumulada en las columnas de vació y al IRG, así continúa hasta el fin del archivo o el fin de carrete. Los datos se organizan como archivos que contiene varios registros de longitud fija o variable, separados por un espacio de 0.75" el IRG. Los datos se graban y leen secuencialmente en las cintas. Si tenemos un archivo de 1000 registros de 80 caracteres habrá espacio desperdiciado por los IRG. Para solucionar podemos crear blocks de 10 registros entonces el espacio desperdiciado será menor.
Cuando un trabajo o job de un usuario requiere unidades de cinta, en la consola aparece los mensajes, el operador coloca los carretes de cinta y las asigna al job para continuar su procesamiento.
De gran importancia cabe mencionar el uso de las cintas para hacer respaldos de datos almacenados en los discos magnéticos, previniendo fallas en los discos y con los respaldos se pueden recuperar los datos.
Equipos de Tarjetas Perforadas
Los dispositivo de entrada lectora de tarjetas 405 y de salida la perforadora de tarjetas 415 y la impresora 512 de hojas de papel son controladas por el programa JANUS. La lectora de tarjetas 405 y perforadora de tarjetas 415 usa una tarjeta de 80 columnas y 12 filas. Para representar datos utiliza el código Holleritht, la tarjeta tiene 3 zonas, la 12, 11 y 0, y las filas restantes 1 a 9. La combinación de perforaciones de zonas y filas representa caracteres. Z12-1=a hasta Z12-9=i, Z11-1=j hasta Z11-9=r, Z0-2=s hasta Z0-9=z. La fila F0=0, F1=1 hasta F9=9. Cada tarjeta mide 7.3" pulgadas de largo, 3.3 " de ancho, 0.007" de espesor, la tarjeta horizontalmente inicia con un espacio de 0.25", continúa perforaciones de 0.5", separadas por 0.03" y termina con un espacio de 0.25".

Los dispositivo de entrada lectora de tarjetas 405 y de salida la perforadora de tarjetas 415 y la impresora 512 de hojas de papel son controladas por el programa JANUS. La lectora de tarjetas 405 y perforadora de tarjetas 415 usa una tarjeta de 80 columnas y 12 filas. Para representar datos utiliza el código Holleritht, la tarjeta tiene 3 zonas, la 12, 11 y 0, y las filas restantes 1 a 9. La combinación de perforaciones de zonas y filas representa caracteres. Z12-1=a hasta Z12-9=i, Z11-1=j hasta Z11-9=r, Z0-2=s hasta Z0-9=z. La fila F0=0, F1=1 hasta F9=9. Cada tarjeta mide 7.3" pulgadas de largo, 3.3 " de ancho, 0.007" de espesor, la tarjeta horizontalmente inicia con un espacio de 0.25", continúa perforaciones de 0.5", separadas por 0.03" y termina con un espacio de 0.25".

Lectora de Tarjetas
La lectora de tarjetas CR 405 está conectada a su controlador y está en la misma unidad. Al colocar un bonche de tarjetas en el casillero de entrada y presionar READY queda lista para recibir comandos del controlador para leer tarjetas, cuando se reciben arranca un motor con poleas y bandas que hacen que las tarjetas sigan una trayectoria desde el casillero de entrada, pasan por una estación de lectura y continúa hasta el casillero de salida. La estación de lectura tiene de un lado un primer diodo sensor de control y a continuación 2 columnas de foto diodos primario y secundario, la primera sirve para leer las tarjetas y con la segunda columna sirve para comparar y detectar errores, sigue un segundo foto diodo sensor de control. Enfrente hay una lámpara de luz que detectan los fotodiodos de la estación de lectura. En uno de los rodillos hay una rueda dentada o con dientes y un pickup detecta los cambios y genera los tiempos para leer y controlar la trayectoria de la tarjeta. Un freno deja pasar las tarjetas una por una y en la estación cada columna de fotodiodos con las perforaciones deja pasar la luz que es detectada como un 1 y si no la dejan pasar es un 0. La tarjeta sigue la trayectoria hasta el casillero de salida. Así continúa leyendo todas las tarjetas. Una tarjeta puede ser de control para requerir alguna actividad al sistema operativo, tal como requerir una unidad de cinta, un archivo de disco, un compilador FORTRAN o COBOL o la ejecución de un programa objeto o binario almacenado en disco. Un conjunto de tarjetas de control representan un trabajo o JOB de programas y datos, la primera tarjeta tiene el nombre del job y algunos otros párametros. El deck de tarjetas son entregados a la ventanilla de operación para procesarse, después de cierto tiempo se recogen los resultados. Al recibir los decks de tarjetas, el operador los coloca en la lectora de tarjetas y se llevan a un archivo en disco INPUT así se van acumulando los jobs, el operador desde la consola los va seleccionando en base a prioridades o de forma automática entran a ejecutarse los trabajos y cada trabajo es asignado a un punto de control para ejecutarse, cuando termina, los resultados se van a un archivo en disco OUTPUT y el operador los va seleccionando para perforarse en una 415 o imprimirse en una 512 y los resultados en tarjetas perforadas o listados son entregados a los usuarios.

La lectora de tarjetas CR 405 está conectada a su controlador y está en la misma unidad. Al colocar un bonche de tarjetas en el casillero de entrada y presionar READY queda lista para recibir comandos del controlador para leer tarjetas, cuando se reciben arranca un motor con poleas y bandas que hacen que las tarjetas sigan una trayectoria desde el casillero de entrada, pasan por una estación de lectura y continúa hasta el casillero de salida. La estación de lectura tiene de un lado un primer diodo sensor de control y a continuación 2 columnas de foto diodos primario y secundario, la primera sirve para leer las tarjetas y con la segunda columna sirve para comparar y detectar errores, sigue un segundo foto diodo sensor de control. Enfrente hay una lámpara de luz que detectan los fotodiodos de la estación de lectura. En uno de los rodillos hay una rueda dentada o con dientes y un pickup detecta los cambios y genera los tiempos para leer y controlar la trayectoria de la tarjeta. Un freno deja pasar las tarjetas una por una y en la estación cada columna de fotodiodos con las perforaciones deja pasar la luz que es detectada como un 1 y si no la dejan pasar es un 0. La tarjeta sigue la trayectoria hasta el casillero de salida. Así continúa leyendo todas las tarjetas. Una tarjeta puede ser de control para requerir alguna actividad al sistema operativo, tal como requerir una unidad de cinta, un archivo de disco, un compilador FORTRAN o COBOL o la ejecución de un programa objeto o binario almacenado en disco. Un conjunto de tarjetas de control representan un trabajo o JOB de programas y datos, la primera tarjeta tiene el nombre del job y algunos otros párametros. El deck de tarjetas son entregados a la ventanilla de operación para procesarse, después de cierto tiempo se recogen los resultados. Al recibir los decks de tarjetas, el operador los coloca en la lectora de tarjetas y se llevan a un archivo en disco INPUT así se van acumulando los jobs, el operador desde la consola los va seleccionando en base a prioridades o de forma automática entran a ejecutarse los trabajos y cada trabajo es asignado a un punto de control para ejecutarse, cuando termina, los resultados se van a un archivo en disco OUTPUT y el operador los va seleccionando para perforarse en una 415 o imprimirse en una 512 y los resultados en tarjetas perforadas o listados son entregados a los usuarios.

Perforadora de tarjetas
La perforadora de tarjetas CP 415 se conecta a su controlador fuera de la unidad. Tiene un mecanismo de movimiento que transporta las tarjetas, en la parte de enfrente tiene un casillero de entrada donde se colocan las tarjetas sin perforar y un motor que mueve poleas, y bandas y rodillos en la trayectoria que siguen las tarjetas hasta el casillero de salida. En la trayectoria hay sensores que detectan cuando se atoren las tarjetas, si sucede para el motor y prende un indicador. En uno de los rodillos en un extremo tiene una rueda dentada y un pickup detecta el movimiento del rodillo y genera los tiempos de control para perforar la tarjeta y transportarla hasta el casillero de salida.
Una vez colocadas las tarjetas se presiona READY y esta lista a recibir comandos del controlador para perforar las tarjetas. Las tarjetas pasan una por una a la estación de perforación y se va perforando fila por fila de 80 columnas hasta la fila12, cuando termina de perforar la tarjeta, la lleva en una trayectoria que la transporta por poleas, bandas y rodillos a un ensamble de escobillas que sirve para leer y comparar las perforaciones y detectar errores, si sucede se prende un indicador y deja de perforar tarjetas, si no hay error la tarjeta es llevada hasta el casillero de salida y así continúa con las siguientes tarjetas hasta que finaliza el programa o las tarjetas se terminan, entonces aparece en la consola de operación un mensaje de falta de tarjetas, el operarador coloca más tarjetas tantas veces sean necesarias y continúa la perforación hasta que termina el programa.


La perforadora de tarjetas CP 415 se conecta a su controlador fuera de la unidad. Tiene un mecanismo de movimiento que transporta las tarjetas, en la parte de enfrente tiene un casillero de entrada donde se colocan las tarjetas sin perforar y un motor que mueve poleas, y bandas y rodillos en la trayectoria que siguen las tarjetas hasta el casillero de salida. En la trayectoria hay sensores que detectan cuando se atoren las tarjetas, si sucede para el motor y prende un indicador. En uno de los rodillos en un extremo tiene una rueda dentada y un pickup detecta el movimiento del rodillo y genera los tiempos de control para perforar la tarjeta y transportarla hasta el casillero de salida.
Una vez colocadas las tarjetas se presiona READY y esta lista a recibir comandos del controlador para perforar las tarjetas. Las tarjetas pasan una por una a la estación de perforación y se va perforando fila por fila de 80 columnas hasta la fila12, cuando termina de perforar la tarjeta, la lleva en una trayectoria que la transporta por poleas, bandas y rodillos a un ensamble de escobillas que sirve para leer y comparar las perforaciones y detectar errores, si sucede se prende un indicador y deja de perforar tarjetas, si no hay error la tarjeta es llevada hasta el casillero de salida y así continúa con las siguientes tarjetas hasta que finaliza el programa o las tarjetas se terminan, entonces aparece en la consola de operación un mensaje de falta de tarjetas, el operarador coloca más tarjetas tantas veces sean necesarias y continúa la perforación hasta que termina el programa.

Impresora de Líneas
La impresora LP 512 tiene de un lado lateral la lógica de la unidad y del otro su controlador. Por el frente tiene el módulo de impresión. Para imprimir se abre el módulo de impresión y se coloca papel de impresión, hay diferentes tamaños, todas tienen pequeñas perforaciones redondas en sus lados laterales y se hacen coincidir e insertan en los dientes de 2 pequeñas cadenas giratorias superiores y en los dientes de 2 pequeñas cadenas giratorias inferiores, son las que van jalando el papel al irse imprimiendo y llevan el pápel hasta la parte trasera de la unidad. Entre el par de pequeñas cadenas giratorias superior e inferior se encuentra una barra de 136 martillos que son las que impactan en los caracteres de la cadena de impresión. El módulo de impresión contiene una cadena de caracteres giratoria, al cerrar el módulo queda muy cerca de la barra de martillos y entre ellos un ribbon de tinta que también gira y las hojas de impresión. Al presionar READY la impresora esta lista para recibir comandos e imprimir sobre el papel una línea de 136 caracteres bajo el control de una cinta de papel perforada de 12 canales, avanza a la siguiente línea se imprime, así continúa hasta el fin de la hoja y salta a la siguiente hoja para imprimirla, así continúa hasta que se termina el programa o el papel, en la consola de operación aparece un mensaje de falta de hojas de impresión, en este caso el operador coloca más papel tantas veces sean necesarias hasta que termine el programa. Las hojas de impresión pueden contener copias con papel carbón entre ellas. Es interesante notar la sincronización exacta de la cadena de caracteres giratoria que contiene un pickup y detecta la posición home de la cadena para generar los tiempos y dar la sincronización exacta, del movimiento del rodillo o ribbon de cinta entintada y el movimiento de las hojas de papel para activar los martillos e imprimir los caracteres exactamente y correctamente.
La impresora LP 512 tiene de un lado lateral la lógica de la unidad y del otro su controlador. Por el frente tiene el módulo de impresión. Para imprimir se abre el módulo de impresión y se coloca papel de impresión, hay diferentes tamaños, todas tienen pequeñas perforaciones redondas en sus lados laterales y se hacen coincidir e insertan en los dientes de 2 pequeñas cadenas giratorias superiores y en los dientes de 2 pequeñas cadenas giratorias inferiores, son las que van jalando el papel al irse imprimiendo y llevan el pápel hasta la parte trasera de la unidad. Entre el par de pequeñas cadenas giratorias superior e inferior se encuentra una barra de 136 martillos que son las que impactan en los caracteres de la cadena de impresión. El módulo de impresión contiene una cadena de caracteres giratoria, al cerrar el módulo queda muy cerca de la barra de martillos y entre ellos un ribbon de tinta que también gira y las hojas de impresión. Al presionar READY la impresora esta lista para recibir comandos e imprimir sobre el papel una línea de 136 caracteres bajo el control de una cinta de papel perforada de 12 canales, avanza a la siguiente línea se imprime, así continúa hasta el fin de la hoja y salta a la siguiente hoja para imprimirla, así continúa hasta que se termina el programa o el papel, en la consola de operación aparece un mensaje de falta de hojas de impresión, en este caso el operador coloca más papel tantas veces sean necesarias hasta que termine el programa. Las hojas de impresión pueden contener copias con papel carbón entre ellas. Es interesante notar la sincronización exacta de la cadena de caracteres giratoria que contiene un pickup y detecta la posición home de la cadena para generar los tiempos y dar la sincronización exacta, del movimiento del rodillo o ribbon de cinta entintada y el movimiento de las hojas de papel para activar los martillos e imprimir los caracteres exactamente y correctamente.
DeadSart Inicio y Carga del Sistema Operativo
En el panel del DS se introduce un pequeño programa de PP utilizando la matrix de 12x12 switchs. Al activar el switch DeadStart el sincronizador de DS precondiciona a los PPs a conectarse son su canal correspondiente PP0-CH0, PP1-CH1... y sus contadores de programa P se ponen en la dirección 0 de su memoria. Cuando se mueve el switch Dead Start PP0 recibe por el canal CH0 las instrucciones del panel DS, cuando termina PP0 de recibir el programita inicia la ejecución de leer de cinta o disco el sistema operativo. Suponiendo que es del disco del sistema, que contiene el sistema operativo con los siguientes programas de MTR, PPR, CMR y la librería de programas del sistema LIB. PP0 inicia la lectura del disco y carga MTR en su memoria y empieza a ejecutarse MTR y aparece en consola varias opciones seleccionar carga automática, para que continue leyendo el sistema operativo y MTR carga el programa residente PPR en todos los PPs e inician su ejecución. Ahora MTR carga a partir de la dirección 0 el residente de memoria central CMR y en la parte superior FBT para controlar y asignar espacio en los discos. En CMR se continúa cargando algunos programas que son muy utilizados por el sistema operativo. Al cargar MTR el residente del PP donde está conectada la consola, PPR residente carga las rutinas transitorias de la consola DSD y queda el PP asignado permanentemente para desplegar y recibir información por la consola.
Cuando se está leyendo del disco, la consola va desplegando en su pantalla izquierda el nombre de los programas que se están cargando. Cuando termina de cargarse el sistema operativo, la consola despliega los display A y B. El display A despliega todas las actividades que hace el sistema operativo cada instante y va creando un archivo DAYFILE. El display B despliega los puntos de control que contienen los programas de los usuarios Prog1, Prog2... que están ejecutándose en memoria central y sus estados en los que se encuentran. Por su teclado se introducen los comandos que controlan el sistema, para ver otros display.
En el panel del DS se introduce un pequeño programa de PP utilizando la matrix de 12x12 switchs. Al activar el switch DeadStart el sincronizador de DS precondiciona a los PPs a conectarse son su canal correspondiente PP0-CH0, PP1-CH1... y sus contadores de programa P se ponen en la dirección 0 de su memoria. Cuando se mueve el switch Dead Start PP0 recibe por el canal CH0 las instrucciones del panel DS, cuando termina PP0 de recibir el programita inicia la ejecución de leer de cinta o disco el sistema operativo. Suponiendo que es del disco del sistema, que contiene el sistema operativo con los siguientes programas de MTR, PPR, CMR y la librería de programas del sistema LIB. PP0 inicia la lectura del disco y carga MTR en su memoria y empieza a ejecutarse MTR y aparece en consola varias opciones seleccionar carga automática, para que continue leyendo el sistema operativo y MTR carga el programa residente PPR en todos los PPs e inician su ejecución. Ahora MTR carga a partir de la dirección 0 el residente de memoria central CMR y en la parte superior FBT para controlar y asignar espacio en los discos. En CMR se continúa cargando algunos programas que son muy utilizados por el sistema operativo. Al cargar MTR el residente del PP donde está conectada la consola, PPR residente carga las rutinas transitorias de la consola DSD y queda el PP asignado permanentemente para desplegar y recibir información por la consola.
Cuando se está leyendo del disco, la consola va desplegando en su pantalla izquierda el nombre de los programas que se están cargando. Cuando termina de cargarse el sistema operativo, la consola despliega los display A y B. El display A despliega todas las actividades que hace el sistema operativo cada instante y va creando un archivo DAYFILE. El display B despliega los puntos de control que contienen los programas de los usuarios Prog1, Prog2... que están ejecutándose en memoria central y sus estados en los que se encuentran. Por su teclado se introducen los comandos que controlan el sistema, para ver otros display.
Entrada, Proceso y Salida de Programas
Cómo se pueden llevar los programas a memoria central y ejecutarse? Hay 3 formas que veremos. Primero recordemos que en ese tiempo los departamentos de Procesamiento de Datos estaban organizados en subdepartamentos o secciones de Analísis y Programación, Producción o Usuarios, Perforación o Captura de Datos y el de Operación.
Cuando se requeria desarrollar una aplicación, era asignado a Análisis y Programación, este seguía un método de desarrollo. Primero se hacía un análisis. Segundo el diseño y programación, Tercero La implementación, producción y mantenimiento del sistema. Una vez hecho el análisis, los programadores utilizaban algún lenguaje de programación, en ese tiempo se usaba FORTRAN o COBOL los programas escribían en formas de codificación y los entregaban a Perforación, después de cierto tiempo lo recogía y los entregaban a Operación por una ventanilla, un operador recibía los decks o bonches de trabajos o Jobs. Después el operador colocaba los decks de tarjetas en el casillero de entrada de la lectora de tarjetas y ponía READY listo para ser leídas por el programa JANUS de forma automática y leía los decks de tarjetas a un archivo INPUT en disco allí se acumulaban los trabajos. El operador de la consola podía seleccionar los trabajos manualmente o de forma automática se asignaban a los puntos de control para ejecutar los decks de tarjetas que podía ser una secuencia de programas que se iban ejecutándose, la primera tarjeta tenía el nombre del job, un nivel de prioridad y otros parámetros. Para los jobs del programador las tarjetas de control llamaban los compiladores de FORTRAN o COBOL que traducían el lenguaje fuente a un lenguaje objeto o de máquina y quedaba como un archivo ejecutable, este era llamado con otra tarjeta para ejecutarse, posiblemente con datos, cuando terminaban los resultados eran almacenados en un archivo OUTPUT en disco. El operador de forma manual iba seleccionando los trabajos de OUTPUT para imprimir o pergorar los resultados. El programador recogía su deck de tarjetas y los resultados en listados, al final del listado aparecía el dayfile de toda la secuencia de ejecución del job indicando si hubo errores compilación u otro tipo de error. El programador los corregía y repetía el procedimiento anterior, tantas veces fueran necesesarias hasta que la aplicación quedaba sin errores y lista para entregarse a producción. Dependiendo de la aplicación se tenían procedimientos para la captura y perforación de los datos y además los horarios para ejecutar los procesos, diario, cada semana o mensualmente. De todas maneras el personal de producción debe capturar en formas los datos, que podían ser pocos o muchos y llevarlos a perforación, cuando están listos se recogen y se entregan en la ventanilla de operación el deck de tarjetas, incluye tarjeta control y datos. Se repite la secuencia de pasos anteriores excepto que las tarjetas de control llaman programas objeto o binario y junto con sus datos se procesan y se obtienen los resultados en listados impresos, son recogidos por personal de producción y finalmente son repartidos a los usuarios de la aplicación.
Terminales Interactivas y Batch
Otra forma de introducir los programas es usando las terminales de comunicaciones locales o remotas. Las locales están cerca de la computadora y los programadores las pueden usar para introducir sus programas y ejecutarlos directamente, sin pasar por perforación y obtener los resultados de sus pruebas más rápido. Cuando la aplicación es terminada, se entrega a producción para procesarlos como se hizo anteriormente, su captura, perforación, entrega a operación para procesarlos y obtener los resultados en hojas impresas y también distribuirlos a los usuarios de la aplicación. Cuando una aplicación se usa en lugares remotos, se utiliza una terminal batch y usa un modem local y una línea telefónica para conectarse en el lugar remoto al modem de la terminal remota que consiste de una consola con teclado, una lectora de tarjetas y una impresora. El operador introduce el deck de tarjetas en la lectora de tarjetas e introduce comandos para enviar el deck a la computadora central y repitir la secuencia de pasos ya visto de procesar los datos y obtener los resultados en listados en hojas de papel, pero ahora se envían por la línea de comunicación hasta la terminal remota y se imprimen en su impresora, los listados son repartidos a los usuarios de la aplicación. Tiempo después con las terminales interactivas locales y remotas más baratas y líneas de comunicaciones más rápidas se va reduciendo los trabajos bach y va aumentando el trabajo interactivo o multiusuarios.
Cómo se pueden llevar los programas a memoria central y ejecutarse? Hay 3 formas que veremos. Primero recordemos que en ese tiempo los departamentos de Procesamiento de Datos estaban organizados en subdepartamentos o secciones de Analísis y Programación, Producción o Usuarios, Perforación o Captura de Datos y el de Operación.
Cuando se requeria desarrollar una aplicación, era asignado a Análisis y Programación, este seguía un método de desarrollo. Primero se hacía un análisis. Segundo el diseño y programación, Tercero La implementación, producción y mantenimiento del sistema. Una vez hecho el análisis, los programadores utilizaban algún lenguaje de programación, en ese tiempo se usaba FORTRAN o COBOL los programas escribían en formas de codificación y los entregaban a Perforación, después de cierto tiempo lo recogía y los entregaban a Operación por una ventanilla, un operador recibía los decks o bonches de trabajos o Jobs. Después el operador colocaba los decks de tarjetas en el casillero de entrada de la lectora de tarjetas y ponía READY listo para ser leídas por el programa JANUS de forma automática y leía los decks de tarjetas a un archivo INPUT en disco allí se acumulaban los trabajos. El operador de la consola podía seleccionar los trabajos manualmente o de forma automática se asignaban a los puntos de control para ejecutar los decks de tarjetas que podía ser una secuencia de programas que se iban ejecutándose, la primera tarjeta tenía el nombre del job, un nivel de prioridad y otros parámetros. Para los jobs del programador las tarjetas de control llamaban los compiladores de FORTRAN o COBOL que traducían el lenguaje fuente a un lenguaje objeto o de máquina y quedaba como un archivo ejecutable, este era llamado con otra tarjeta para ejecutarse, posiblemente con datos, cuando terminaban los resultados eran almacenados en un archivo OUTPUT en disco. El operador de forma manual iba seleccionando los trabajos de OUTPUT para imprimir o pergorar los resultados. El programador recogía su deck de tarjetas y los resultados en listados, al final del listado aparecía el dayfile de toda la secuencia de ejecución del job indicando si hubo errores compilación u otro tipo de error. El programador los corregía y repetía el procedimiento anterior, tantas veces fueran necesesarias hasta que la aplicación quedaba sin errores y lista para entregarse a producción. Dependiendo de la aplicación se tenían procedimientos para la captura y perforación de los datos y además los horarios para ejecutar los procesos, diario, cada semana o mensualmente. De todas maneras el personal de producción debe capturar en formas los datos, que podían ser pocos o muchos y llevarlos a perforación, cuando están listos se recogen y se entregan en la ventanilla de operación el deck de tarjetas, incluye tarjeta control y datos. Se repite la secuencia de pasos anteriores excepto que las tarjetas de control llaman programas objeto o binario y junto con sus datos se procesan y se obtienen los resultados en listados impresos, son recogidos por personal de producción y finalmente son repartidos a los usuarios de la aplicación.
Terminales Interactivas y Batch
Otra forma de introducir los programas es usando las terminales de comunicaciones locales o remotas. Las locales están cerca de la computadora y los programadores las pueden usar para introducir sus programas y ejecutarlos directamente, sin pasar por perforación y obtener los resultados de sus pruebas más rápido. Cuando la aplicación es terminada, se entrega a producción para procesarlos como se hizo anteriormente, su captura, perforación, entrega a operación para procesarlos y obtener los resultados en hojas impresas y también distribuirlos a los usuarios de la aplicación. Cuando una aplicación se usa en lugares remotos, se utiliza una terminal batch y usa un modem local y una línea telefónica para conectarse en el lugar remoto al modem de la terminal remota que consiste de una consola con teclado, una lectora de tarjetas y una impresora. El operador introduce el deck de tarjetas en la lectora de tarjetas e introduce comandos para enviar el deck a la computadora central y repitir la secuencia de pasos ya visto de procesar los datos y obtener los resultados en listados en hojas de papel, pero ahora se envían por la línea de comunicación hasta la terminal remota y se imprimen en su impresora, los listados son repartidos a los usuarios de la aplicación. Tiempo después con las terminales interactivas locales y remotas más baratas y líneas de comunicaciones más rápidas se va reduciendo los trabajos bach y va aumentando el trabajo interactivo o multiusuarios.
Multiprogramación
La multiprogramación es cuando varios programas se están ejecutando en la memoria central. Sabemos que MTR controla todo el sistema. Cuando los programas se ejecutan en memoria MTR los asigna a los puntos de control y de forma concurrente se están ejecutando aparentemente todos al mismo tiempo. En realidad MTR asigna a cada programa un slice time o pedazo de tiempo para accesar el CPU y ejecutar el programa, cuando termina su tiempo se pasa a otro programa para continuar ejecutándose. El cambio de un programa a otro lo realiza MTR con la instrucción salto de intercambio EXJ. Cada programa tiene en CMR un área o paquete de intercambio EXJ donde guarda los valores de los registros A, B y X del CPU, su RA y FL y el contador del programa PC que indica la dirección en memoria central CM donde está la siguiente palabra de instrucciones y datos a ejecutar. Cuando MTR ejecuta la instrucción EXJ interrumpe un programa en ejecución, toma los valores A, B, X, RA, FL, PC y otros datos y los coloca en su paquete de intercambio EXJ. MTR pasa el control a otro, llevando los valores guardados en su paquete de intercambio EXJ de A, B, X, RA, FL, PC y los coloca en los registros del CPU y continúa la ejecución del programa en la dirección de PC.
MTR ejecuta una secuencia repetitiva de instrucciones o loop que checan a cada programa en sus puntos de control y ve si requiere algún servicio. Por ejemplo el Prog3 asignado al punto de control3 con una área de memoria que inicia en una dirección de referencia RA y una longitud FL cuando el Prog3 detecta un error, en RA pone el error, cuando MTR en su recorrido ve el mensaje en RA del Prog3 puede abortar el programa o dar alguna solución. Si requiere datos en RA+1 pone la petición CIO para leer o escribir datos en los dispositivos periféricos y sus parámetros de FIRST, IN, OUT Y LIMIT. CIO es una área de memoria circular que inicia en FIRST y termina en LIMIT el flujo de datos es de FIRST a LIMIT y entre ellos los apuntadores IN que inicia los datos hasta OUT, cuando se inicia FIRST=IN=OUT al poner un dato en IN se incrementa en 1 así continua poniendo datos hasta cuando IN=LIMIT da la vuelta y ahora IN=FIRST, siempre y cuando de OUT se saquen datos y se va incrementando en 1 es decir OUT va siguiendo a IN y van dando vueltas. Para un archivo en disco supongamos el tamaño de CIO es de 64 palabras o un PRU. Un PP escribe a partir de la dirección IN un PRU de 64 palabras de los datos obtenidos de un disco y el programa de CPU lee datos a partir de la dirección OUT. También el caso de un programa de CPU que escribe 64 palabras datos en la dirección IN y un PP los lee de OUT para llevarlos los datos a un disco. Entonces MTR en su recorrido cuando pasa por el Prog3 ve que hay una petición de datos. Pero sabemos que leer o escribir datos en algún equipo periférico lleva mucho tiempo en comparación con el tiempo de ejecución del CPU. Por lo tanto MTR avisa a Prog3 que le dará el servicio de llevarle datos, pero lo sacará de ejecución y lo pondrá en estado de espera por datos y el control lo dará a otro programa ejecutando un EXJ. En CMR hay una área de comunicación de MTR y los PP. Para cada PP hay un área que tiene un registro de entrada, un registro de salida y un área de mensajes. MTR para dar el servicio busca un PP libre, al encontrarlo pone en su registro de entrada la petición de leer o escribir datos en algún periférico. Sabemos que los PPs tienen el programa residente PPR y también tiene una secuencia de instrucciones repetitivas o loop que checa su área de comunicación para ver en su registro de entrada si tiene un trabajo asignado por MTR y usa el registro de salida para requerir un servicio o informar a MTR. En este caso PPR ve que MTR le asigno el trabajo de leer de un disco datos. PPR busca la rutina transitoria en CMR o en la librería del sistema en disco, cuando encuentra la rutina 1RS la lleva al área de memoria donde se cargan las rutinas trasitorias y overlays o traslapes, entonces le pasa el control a la rutina transitoria, está determina si puede realizar el trabajo o debe llamar un overlay para realizarlo.
También 1RS puede quedar asignada permanentemente al PP para dar más rápidamente el servicio. Supongamos que la rutina puede realizar el trabajo de leer de disco. Recordemos que los PPs están girando en el barril y dan una vuelta en 1000 nseg y cada PP tiene un Slot Time de 100 nseg para ejecutar sus instrucciones. Además solo se puede leer sectores de los discos, dando el cilindro y track donde se encuentra el sector que tiene 640 caracteres de datos en código display de 6 bits. También al sector se le llama un Phisical Record Unit PRU de 64 palabras de 60 bits, en una palabra caben 10 caracteres por lo tanto un PRU tiene 640 caracteres. El tiempo de buscar, encontrar y transferir un sector es digamos de 50 mseg. primero se lleva a la memoria del PP y luego en blocks de 5 palabras de 12 bits forman una palabra de 60 bits y se lleva al área de memoria circular CIO, hasta completar 64 palabras de un PRU, comparado con la velocidad del CPU el tiempo es muy grande. Por lo tanto la rutina transitoria nececita varias vueltas en el barril para leer los datos y llevarlos al área de datos CIO a partir de la dirección IN del Prog3, al terminar la rutina transitoria pasa el control a PPR y este pone un mensaje en su registro de salida. MTR en su recorrido ve el registro de salida del PP que terminó la transferencia de datos y debe avisar a Prog3. Para eso debe reiniciar la ejecución de Prog3, entonces detiene algún otro programa y ejecuta un EXJ para que continúe la ejecución del Prog3 con los datos obtenidos de la dirección OUT de la memoria circular CIO. Para otra forma de datos de cintas, tarjetas o terminales es parecido la secuencia descrita pero no igual. El sacar un programa ROLL-OUT y llevarlo al ECS o un disco para guardarlo y regresarlo ROLL-IN para continuar ejecutándose en el mismo punto de control se puede hacer de forma manual o automática. También existe el proceso de sacar el programa SWAP-OUT completo y almacenarse en el ECS o disco y regresarlo SWAP-IN a otro punto de control para continuar su ejecución.
Así continúa el sistema operativo recibiendo trabajos en la entrada, procesando los trabajos y obteniendo en la salida los resultados en un ambiente de multiprogramación. Cuando hay dos CPUs el sistema operativo asigna trabajos a los CPUs en un ambiente de multiprocesamiento y multiprogramación. Para complicarlo más si consideramos a usuarios trabajando en terminales locales y remotas se agrega un ambiente de multiusuarios y tiempo compartido.
Es interesante ver la complejidad de la arquitectura y organización del sistema CDC6000 y de la creatividad y originalidad de los diseñadores del sistema Seymour R. Cray y J. E. Thornton.
La arquitéctura y organización del sistema CDC6000 fue la base del desarrollo de los sistemas de CDC posteriores CDC7000, CYBER70 (72-6200 73-6400 74-6600 76-7600 y opciones para tener 2 procesadores) CYBER170 (173-6400 174-6600 176-7600 y 720 730 740 y opciones para tener 2 procesadores ) CYBER180 y CYBER190.
La multiprogramación es cuando varios programas se están ejecutando en la memoria central. Sabemos que MTR controla todo el sistema. Cuando los programas se ejecutan en memoria MTR los asigna a los puntos de control y de forma concurrente se están ejecutando aparentemente todos al mismo tiempo. En realidad MTR asigna a cada programa un slice time o pedazo de tiempo para accesar el CPU y ejecutar el programa, cuando termina su tiempo se pasa a otro programa para continuar ejecutándose. El cambio de un programa a otro lo realiza MTR con la instrucción salto de intercambio EXJ. Cada programa tiene en CMR un área o paquete de intercambio EXJ donde guarda los valores de los registros A, B y X del CPU, su RA y FL y el contador del programa PC que indica la dirección en memoria central CM donde está la siguiente palabra de instrucciones y datos a ejecutar. Cuando MTR ejecuta la instrucción EXJ interrumpe un programa en ejecución, toma los valores A, B, X, RA, FL, PC y otros datos y los coloca en su paquete de intercambio EXJ. MTR pasa el control a otro, llevando los valores guardados en su paquete de intercambio EXJ de A, B, X, RA, FL, PC y los coloca en los registros del CPU y continúa la ejecución del programa en la dirección de PC.
MTR ejecuta una secuencia repetitiva de instrucciones o loop que checan a cada programa en sus puntos de control y ve si requiere algún servicio. Por ejemplo el Prog3 asignado al punto de control3 con una área de memoria que inicia en una dirección de referencia RA y una longitud FL cuando el Prog3 detecta un error, en RA pone el error, cuando MTR en su recorrido ve el mensaje en RA del Prog3 puede abortar el programa o dar alguna solución. Si requiere datos en RA+1 pone la petición CIO para leer o escribir datos en los dispositivos periféricos y sus parámetros de FIRST, IN, OUT Y LIMIT. CIO es una área de memoria circular que inicia en FIRST y termina en LIMIT el flujo de datos es de FIRST a LIMIT y entre ellos los apuntadores IN que inicia los datos hasta OUT, cuando se inicia FIRST=IN=OUT al poner un dato en IN se incrementa en 1 así continua poniendo datos hasta cuando IN=LIMIT da la vuelta y ahora IN=FIRST, siempre y cuando de OUT se saquen datos y se va incrementando en 1 es decir OUT va siguiendo a IN y van dando vueltas. Para un archivo en disco supongamos el tamaño de CIO es de 64 palabras o un PRU. Un PP escribe a partir de la dirección IN un PRU de 64 palabras de los datos obtenidos de un disco y el programa de CPU lee datos a partir de la dirección OUT. También el caso de un programa de CPU que escribe 64 palabras datos en la dirección IN y un PP los lee de OUT para llevarlos los datos a un disco. Entonces MTR en su recorrido cuando pasa por el Prog3 ve que hay una petición de datos. Pero sabemos que leer o escribir datos en algún equipo periférico lleva mucho tiempo en comparación con el tiempo de ejecución del CPU. Por lo tanto MTR avisa a Prog3 que le dará el servicio de llevarle datos, pero lo sacará de ejecución y lo pondrá en estado de espera por datos y el control lo dará a otro programa ejecutando un EXJ. En CMR hay una área de comunicación de MTR y los PP. Para cada PP hay un área que tiene un registro de entrada, un registro de salida y un área de mensajes. MTR para dar el servicio busca un PP libre, al encontrarlo pone en su registro de entrada la petición de leer o escribir datos en algún periférico. Sabemos que los PPs tienen el programa residente PPR y también tiene una secuencia de instrucciones repetitivas o loop que checa su área de comunicación para ver en su registro de entrada si tiene un trabajo asignado por MTR y usa el registro de salida para requerir un servicio o informar a MTR. En este caso PPR ve que MTR le asigno el trabajo de leer de un disco datos. PPR busca la rutina transitoria en CMR o en la librería del sistema en disco, cuando encuentra la rutina 1RS la lleva al área de memoria donde se cargan las rutinas trasitorias y overlays o traslapes, entonces le pasa el control a la rutina transitoria, está determina si puede realizar el trabajo o debe llamar un overlay para realizarlo.
También 1RS puede quedar asignada permanentemente al PP para dar más rápidamente el servicio. Supongamos que la rutina puede realizar el trabajo de leer de disco. Recordemos que los PPs están girando en el barril y dan una vuelta en 1000 nseg y cada PP tiene un Slot Time de 100 nseg para ejecutar sus instrucciones. Además solo se puede leer sectores de los discos, dando el cilindro y track donde se encuentra el sector que tiene 640 caracteres de datos en código display de 6 bits. También al sector se le llama un Phisical Record Unit PRU de 64 palabras de 60 bits, en una palabra caben 10 caracteres por lo tanto un PRU tiene 640 caracteres. El tiempo de buscar, encontrar y transferir un sector es digamos de 50 mseg. primero se lleva a la memoria del PP y luego en blocks de 5 palabras de 12 bits forman una palabra de 60 bits y se lleva al área de memoria circular CIO, hasta completar 64 palabras de un PRU, comparado con la velocidad del CPU el tiempo es muy grande. Por lo tanto la rutina transitoria nececita varias vueltas en el barril para leer los datos y llevarlos al área de datos CIO a partir de la dirección IN del Prog3, al terminar la rutina transitoria pasa el control a PPR y este pone un mensaje en su registro de salida. MTR en su recorrido ve el registro de salida del PP que terminó la transferencia de datos y debe avisar a Prog3. Para eso debe reiniciar la ejecución de Prog3, entonces detiene algún otro programa y ejecuta un EXJ para que continúe la ejecución del Prog3 con los datos obtenidos de la dirección OUT de la memoria circular CIO. Para otra forma de datos de cintas, tarjetas o terminales es parecido la secuencia descrita pero no igual. El sacar un programa ROLL-OUT y llevarlo al ECS o un disco para guardarlo y regresarlo ROLL-IN para continuar ejecutándose en el mismo punto de control se puede hacer de forma manual o automática. También existe el proceso de sacar el programa SWAP-OUT completo y almacenarse en el ECS o disco y regresarlo SWAP-IN a otro punto de control para continuar su ejecución.
Así continúa el sistema operativo recibiendo trabajos en la entrada, procesando los trabajos y obteniendo en la salida los resultados en un ambiente de multiprogramación. Cuando hay dos CPUs el sistema operativo asigna trabajos a los CPUs en un ambiente de multiprocesamiento y multiprogramación. Para complicarlo más si consideramos a usuarios trabajando en terminales locales y remotas se agrega un ambiente de multiusuarios y tiempo compartido.
Es interesante ver la complejidad de la arquitectura y organización del sistema CDC6000 y de la creatividad y originalidad de los diseñadores del sistema Seymour R. Cray y J. E. Thornton.
La arquitéctura y organización del sistema CDC6000 fue la base del desarrollo de los sistemas de CDC posteriores CDC7000, CYBER70 (72-6200 73-6400 74-6600 76-7600 y opciones para tener 2 procesadores) CYBER170 (173-6400 174-6600 176-7600 y 720 730 740 y opciones para tener 2 procesadores ) CYBER180 y CYBER190.
Al
principio comparamos el sistema CDC6000 con un teléfono inteligente,
solo con el fin de ver como se ha desarrollado las tecnologías de
electrónica, comunicaciones y computación, como resultado hoy tenemos
en la palma de la mano una pequeña super computadora disponible y
accesible a toda las personas que lo deseen.
Por ejemplo el teléfono inteligente Samsung Galaxy III mini tiene las siguientes características.
Anunciado en Octubre 2012
TAMAÑO Dimensiones 121.5x63x 9.8 mm Peso 111.5 g
COMUNICACIONES
RED TELEFONICA
GSM 850/900/1800/1900
HSDPA 900/1900/2100
RED LOCAL
- Wi-Fi 802.11 a/b/g/n; DLNA; Wi-Fi Direct
- Bluetooth v4.0 A2DP, LE, EDR
Por ejemplo el teléfono inteligente Samsung Galaxy III mini tiene las siguientes características.
Anunciado en Octubre 2012
TAMAÑO Dimensiones 121.5x63x 9.8 mm Peso 111.5 g
COMUNICACIONES
RED TELEFONICA
GSM 850/900/1800/1900
HSDPA 900/1900/2100
RED LOCAL
- Wi-Fi 802.11 a/b/g/n; DLNA; Wi-Fi Direct
- Bluetooth v4.0 A2DP, LE, EDR
COMPUTACION
Chipset SOC NovaThor U8420
CPU 1 GHz dual-core Cortex-A9
GPU Mali-400
Memoria interna, 1GB de RAM
Slot de tarjeta microSD 8/16/32GB
MicroUSB 2.0
DISPLAY
Tipo Super AMOLED touchscreen capacitivo, 16M de colores.
Tamaño 480 x 800 pixels, 4.0 pulgadas
- Sensor acelerómetro para auto rotación
- Controles sensibles al tacto
- Soporte multitouch
- Interfaz de usuario TouchWiz
AUDIO
RINGTONES Tipo Polifónico, MP3, WAV
- Conector de audio 3.5 mm
- Reproductor de audio MP3/WAV/eAAC+/AC3/FLAC
- Radio FM Stereo con RDS
FOTOS
Cámara 5 MP, 2592x1944 pixels,
autofocus, flash LED, geo-tagging,
detección de rostro, foco táctil, video
720p@30fps, cámara frontal VGA
GPS
- Con soporte A-GPS
- Brújula digital
- Cancelación activa de ruido con micrófono dedicado
VIDEO
Reproductor de video MP4/DivX/XviD/WMV/H.264/H.263
BATERÍA Standard, Li-Ion 1500 mAh
Inactivo 450 h(2G) / 430 h (3G)
Activo 14 h10min(2G)/7h10min (3G)
Chipset SOC NovaThor U8420
CPU 1 GHz dual-core Cortex-A9
GPU Mali-400
Memoria interna, 1GB de RAM
Slot de tarjeta microSD 8/16/32GB
MicroUSB 2.0
DISPLAY
Tipo Super AMOLED touchscreen capacitivo, 16M de colores.
Tamaño 480 x 800 pixels, 4.0 pulgadas
- Sensor acelerómetro para auto rotación
- Controles sensibles al tacto
- Soporte multitouch
- Interfaz de usuario TouchWiz
AUDIO
RINGTONES Tipo Polifónico, MP3, WAV
- Conector de audio 3.5 mm
- Reproductor de audio MP3/WAV/eAAC+/AC3/FLAC
- Radio FM Stereo con RDS
FOTOS
Cámara 5 MP, 2592x1944 pixels,
autofocus, flash LED, geo-tagging,
detección de rostro, foco táctil, video
720p@30fps, cámara frontal VGA
GPS
- Con soporte A-GPS
- Brújula digital
- Cancelación activa de ruido con micrófono dedicado
VIDEO
Reproductor de video MP4/DivX/XviD/WMV/H.264/H.263
BATERÍA Standard, Li-Ion 1500 mAh
Inactivo 450 h(2G) / 430 h (3G)
Activo 14 h10min(2G)/7h10min (3G)
SOFTWARE
OS Android OS, v4.1 Jelly Bean
Mensajería SMS, MMS, Email
Navegador HTML5
Agenda telefónica
Integración con redes sociales FACEBOOK, MESSANGER, TWITTER
Pasatiempo con Juegos
Organizador y Visor de documentos FPD,WORD, Texto
Paquetes de negocios OFFICE
Integración Google Search, Maps, Gmail, YouTube, Calendar, Google Talk, Picasa
Acceso a Play Store para carga de aplicaciones gratis y de pago
Desarrollo de programas AIDE, CCTOOLS
Desarrollo de aplicaciones en internet con el paquete PWS Palapa Web Server con el servidor web APACHE, el lenguaje de programación PHP y la base de datos MYSQL.
OS Android OS, v4.1 Jelly Bean
Mensajería SMS, MMS, Email
Navegador HTML5
Agenda telefónica
Integración con redes sociales FACEBOOK, MESSANGER, TWITTER
Pasatiempo con Juegos
Organizador y Visor de documentos FPD,WORD, Texto
Paquetes de negocios OFFICE
Integración Google Search, Maps, Gmail, YouTube, Calendar, Google Talk, Picasa
Acceso a Play Store para carga de aplicaciones gratis y de pago
Desarrollo de programas AIDE, CCTOOLS
Desarrollo de aplicaciones en internet con el paquete PWS Palapa Web Server con el servidor web APACHE, el lenguaje de programación PHP y la base de datos MYSQL.
No hay comentarios:
Publicar un comentario